Golang 协程/线程/进程 区别详解
转载请注明来源:janrs.com/mffp
概念
进程 每个进程都有自己的独立内存空间,拥有自己独立的地址空间、独立的堆和栈,既不共享堆,亦不共享栈。一个程序至少有一个进程,一个进程至少有一个线程。进程切换只发生在内核态。
线程 线程拥有自己独立的栈和共享的堆,共享堆,不共享栈,是由操作系统调度,是操作系统调度(CPU调度)执行的最小单位。对于进程和线程,都是有内核进行调度,有 CPU 时间片的概念, 进行抢占式调度。内核由系统内核进行调度, 系统为了实现并发,会不断地切换线程执行, 由此会带来线程的上下文切换。
协程 协程线程一样共享堆,不共享栈,协程是由程序员在协程的代码中显示调度。协程(用户态线程)是对内核透明的, 也就是系统完全不知道有协程的存在, 完全由用户自己的程序进行调度。在栈大小分配方便,且每个协程占用的默认占用内存很小,只有 2kb ,而线程需要 8mb,相较于线程,因为协程是对内核透明的,所以栈空间大小可以按需增大减小。
并发 多线程程序在单核上运行
并行 多线程程序在多核上运行
协程与线程主要区别是它将不再被内核调度,而是交给了程序自己而线程是将自己交给内核调度,所以golang中就会有调度器的存在。
详解
进程
在计算机中,单个 CPU 架构下,每个 CPU 同时只能运行一个任务,也就是同时只能执行一个计算。如果一个进程跑着,就把唯一一个 CPU 给完全占住,显然是不合理的。而且很大概率上,CPU 被阻塞了,不是因为计算量大,而是因为网络阻塞。如果此时 CPU 一直被阻塞着,其他进程无法使用,那么计算机资源就是浪费了。
这就出现了多进程调用了。多进程就是指计算机系统可以同时执行多个进程,从一个进程到另外一个进程的转换是由操作系统内核管理的,一般是同时运行多个软件。
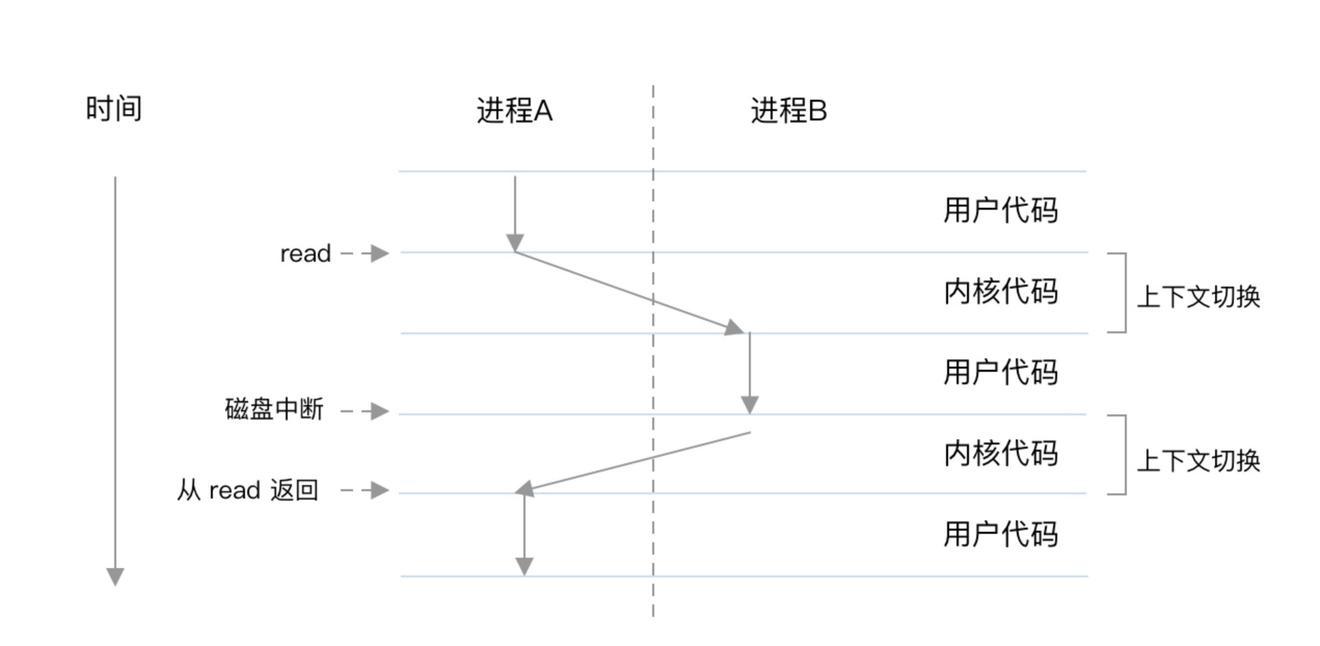
线程
有了多进程,为什么还要线程?原因如下:
- 进程间的信息难以共享数据,父子进程并未共享内存,需要通过进程间通信(IPC),在进程间进行信息交换,性能开销较大。
- 创建进程(一般是调用 fork 方法)的性能开销较大。
在一个进程内,可以设置多个执行单元,这个执行单元都运行在进程的上下文中,共享着同样的代码和全局数据,由于是在全局共享的,就不存在像进程间信息交换的性能损耗,所以性能和效率就更高了。这个运行在进程中的执行单元就是线程。

协程
官方的解释:链接:goroutines说明
Goroutines 是使并发易于使用的一部分。 这个想法已经存在了一段时间,就是将独立执行的函数(协程)多路复用到一组线程上。 当协程阻塞时,例如通过调用阻塞系统调用,运行时会自动将同一操作系统线程上的其他协程移动到不同的可运行线程,这样它们就不会被阻塞。 程序员看不到这些,这就是重点。 我们称之为 goroutines 的结果可能非常便宜:除了堆栈的内存之外,它们的开销很小,只有几千字节。为了使堆栈变小,Go的运行时使用可调整大小的有界堆栈。 一个新创建的goroutine被赋予几千字节,这几乎总是足够的。 如果不是,运行时会自动增加(和缩小)用于存储堆栈的内存,从而允许许多goroutine存在于适度的内存中。 每个函数调用的CPU开销平均约为三个廉价指令。 在同一个地址空间中创建数十万个goroutine是很实际的。 如果goroutines只是线程,系统资源会以更少的数量耗尽。
从官方的解释中可以看到,协程是通过多路复用到一组线程上,所以本质上,协程就是轻量级的线程。但是必须要区分的一点是,协程是用用户态的,进程跟线程都是内核态,这点非常重要,这也是协程为什么高效的原因。
协程的优势如下:
- 节省
CPU:避免系统内核级的线程频繁切换,造成的CPU资源浪费。协程是用户态的线程,用户可以自行控制协程的创建于销毁,极大程度避免了系统级线程上下文切换造成的资源浪费。 - 节约内存:在
64位的Linux中,一个线程需要分配8MB栈内存和64MB堆内存,系统内存的制约导致我们无法开启更多线程实现高并发。而在协程编程模式下,只需要几千字节(执行Go协程只需要极少的栈内存,大概4~5KB,默认情况下,线程栈的大小为1MB)可以轻松有十几万协程,这是线程无法比拟的。 - 开发效率:使用协程在开发程序之中,可以很方便的将一些耗时的
IO操作异步化,例如写文件、耗时IO请求等。并且它们并不是被操作系统所调度执行,而是程序员手动可以进行调度的。 - 高效率:协程之间的切换发生在用户态,在用户态没有时钟中断,系统调用等机制,因此效率高。
[Golang三关-典藏版] Golang 调度器 GMP 原理与调度全分析
简介
G表示:goroutine,即Go协程,每个go关键字都会创建一个协程。M表示:thread内核级线程,所有的G都要放在M上才能运行。P表示:processor处理器,调度G到M上,其维护了一个队列,存储了所有需要它来调度的G。
Goroutine 调度器 P 和 OS 调度器是通过 M 结合起来的,每个 M 都代表了 1 个内核线程,OS 调度器负责把内核线程分配到 CPU 的核上执行,
线程和协程的映射关系
在上面的 Golang 官方关于协程的解释中提到:
将独立执行的函数(协程)多路复用到一组线程上。 当协程阻塞时,例如通过调用阻塞系统调用,运行时会自动将同一操作系统线程上的其他协程移动到不同的可运行线程,这样它们就不会被阻塞。
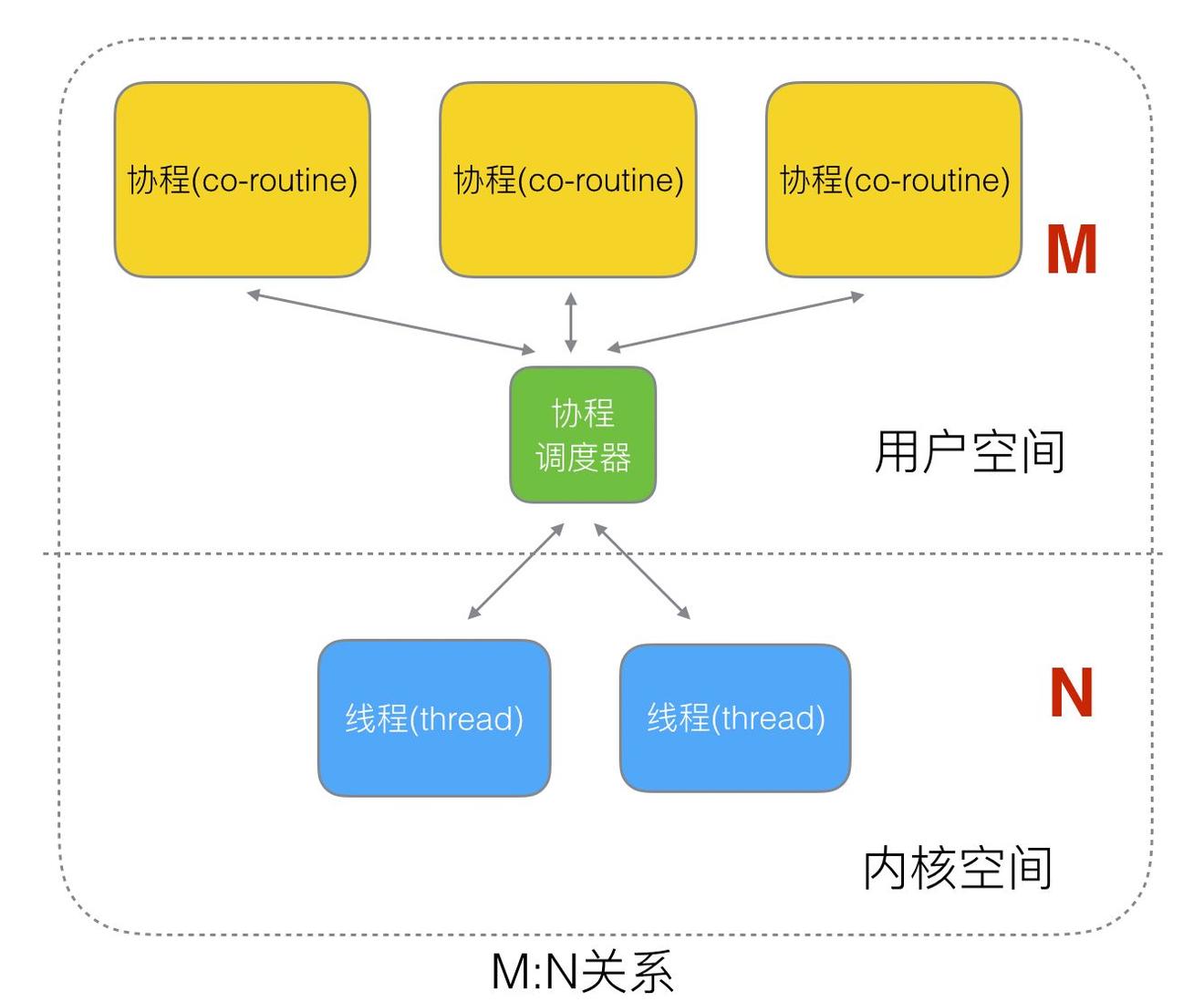
也就是说,协程的执行是需要通过线程来先实现的。下图表示的映射关系:
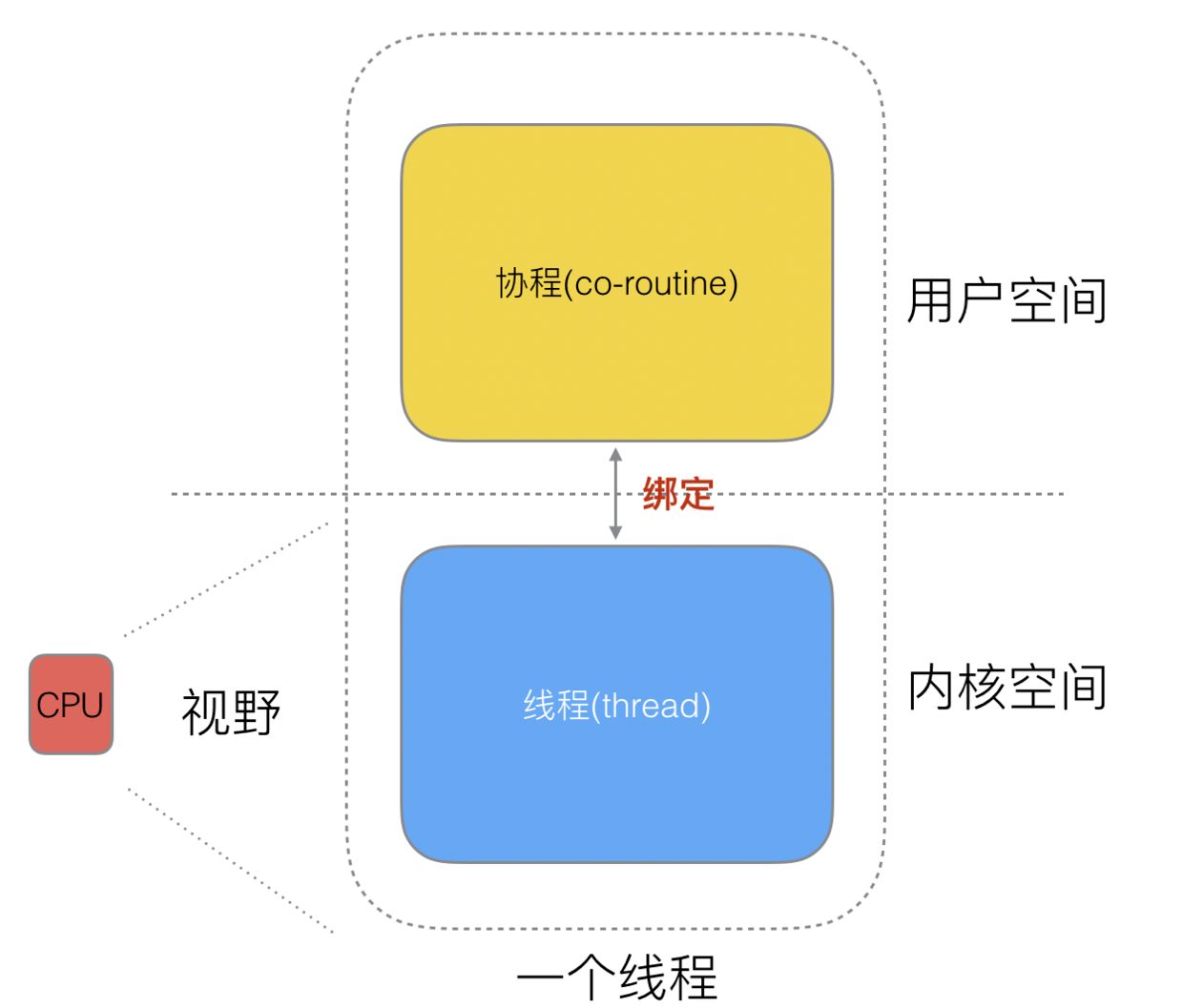
在协程和线程的映射关系中,有以下三种:
N:1关系1:1关系M:N关系
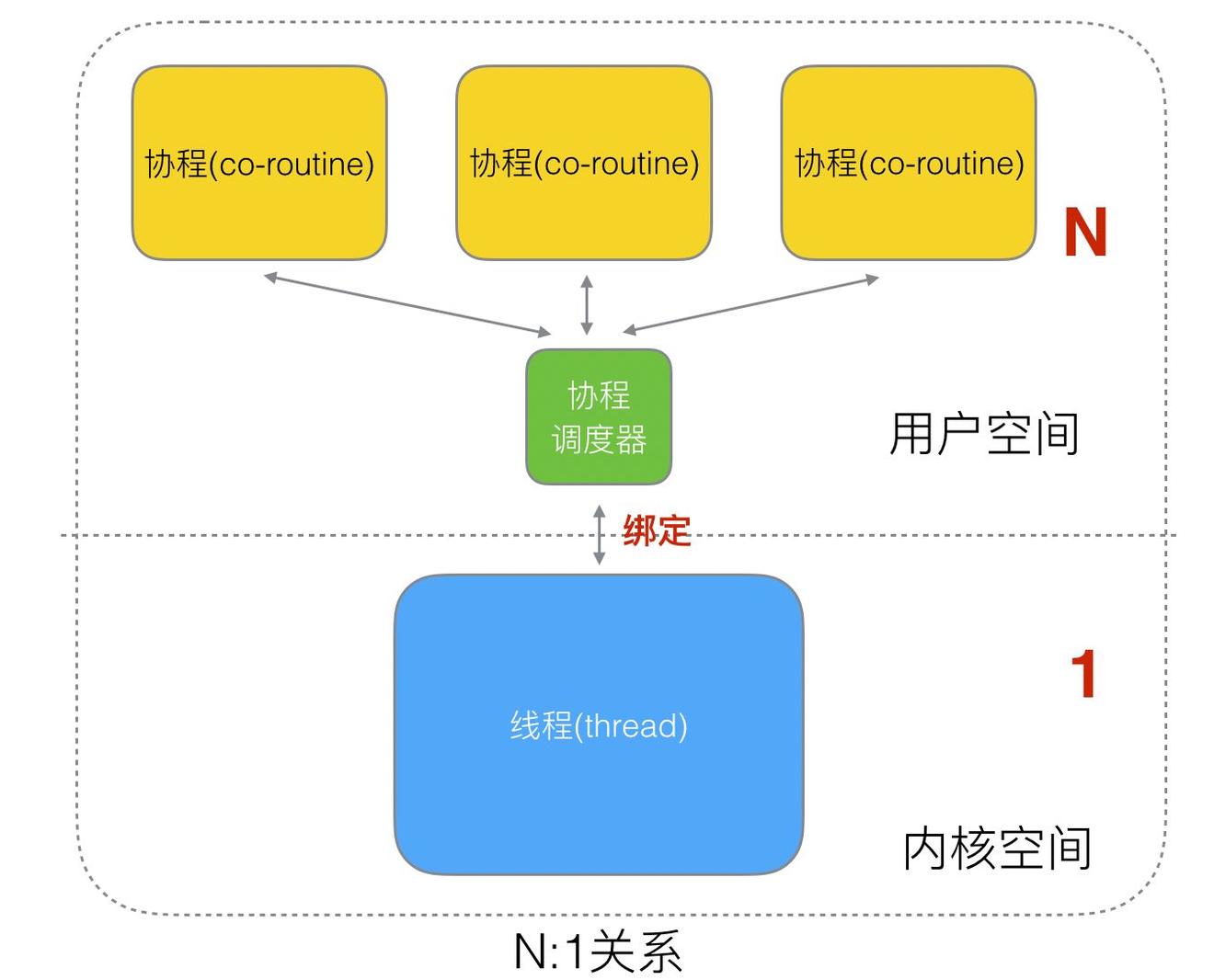
N:1 关系
N 个协程绑定 1 个线程,优点就是协程在用户态线程即完成切换,不会陷入到内核态,这种切换非常的轻量快速。但也有很大的缺点,1 个进程的所有协程都绑定在 1 个线程上。
缺点:
- 某个程序用不了硬件的多核加速能力
- 一旦某协程阻塞,造成线程阻塞,本进程的其他协程都无法执行了,根本就没有并发的能力了。
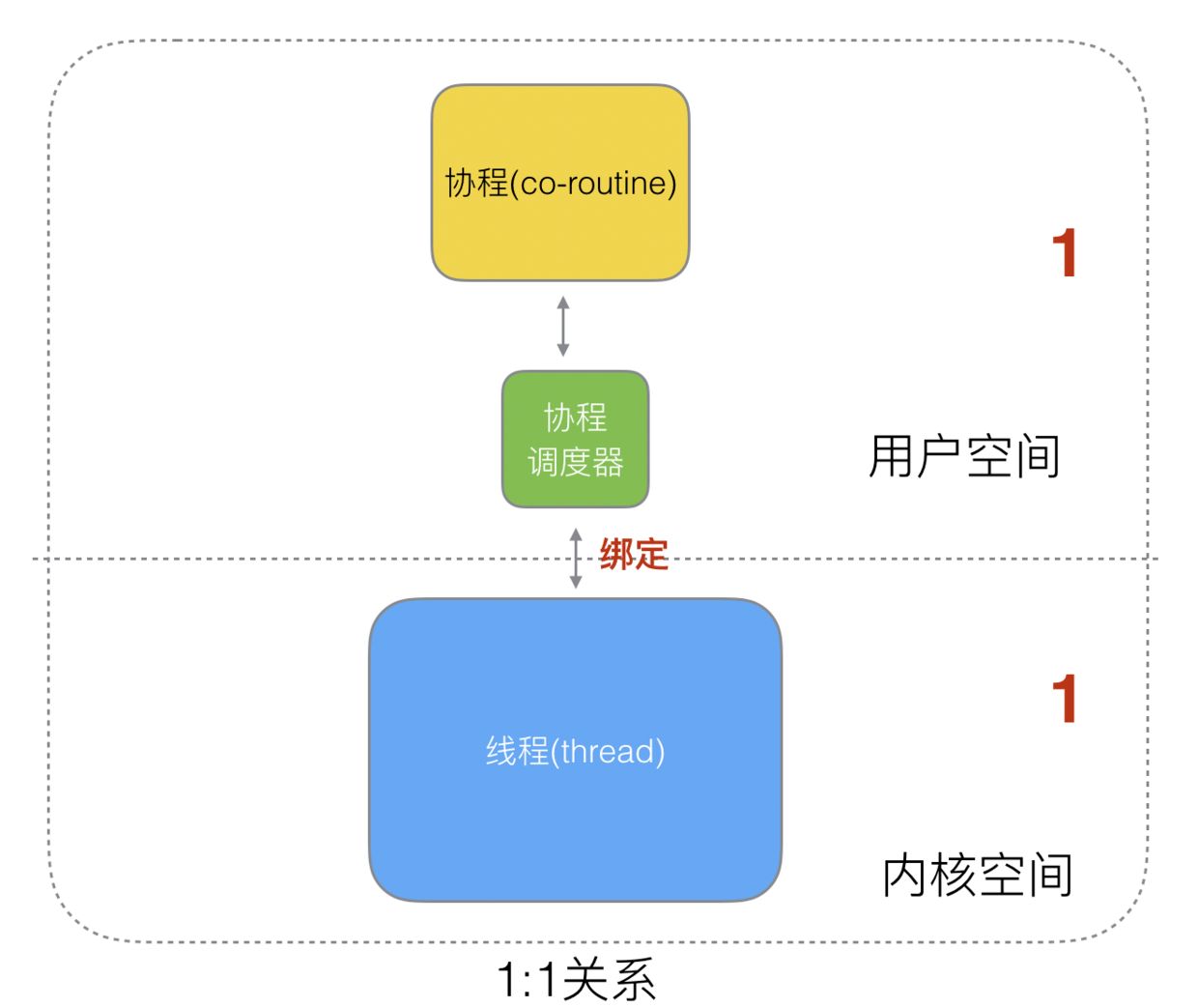
1:1 关系
1 个协程绑定 1 个线程,这种最容易实现。协程的调度都由 CPU 完成了,不存在 N:1 缺点。
缺点:
- 协程的创建、删除和切换的代价都由
CPU完成,有点略显昂贵了。
M:N 关系
M 个协程绑定 1 个线程,是 N:1 和 1:1 类型的结合,克服了以上 2 种模型的缺点,但实现起来最为复杂。
协程跟线程是有区别的,线程由 CPU 调度是抢占式的,协程由用户态调度是协作式的,一个协程让出 CPU 后,才执行下一个协程。
调度器实现原理
注:Go目前使用的调度器是2012年重新设计的。
2012 之前的调度原理,如下图所示:
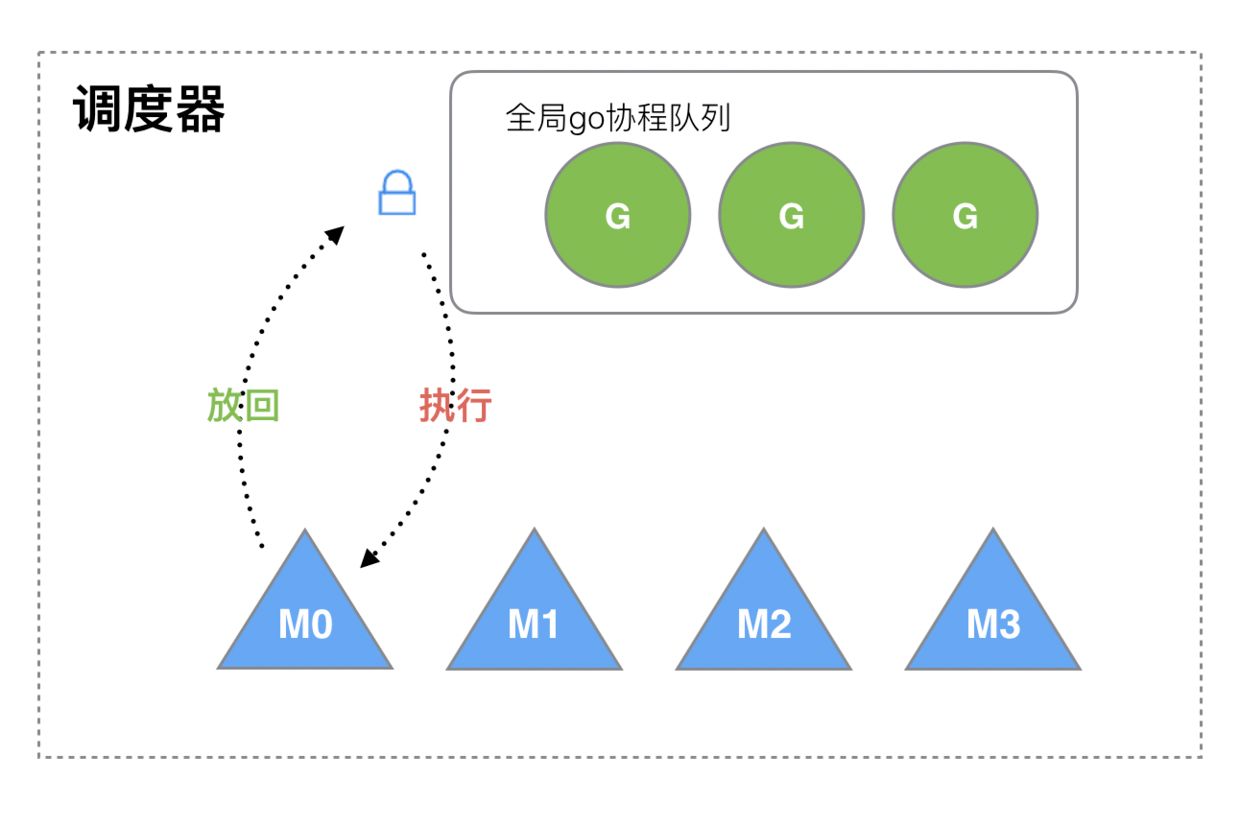
M 想要执行、放回 G 都必须访问全局 G 队列,并且 M 有多个,即多线程访问同一资源需要加锁进行保证互斥 / 同步,所以全局 G 队列是有互斥锁进行保护的。
缺点:
- 创建、销毁、调度
G都需要每个M获取锁,这就形成了激烈的锁竞争。 M转移G会造成延迟和额外的系统负载。比如当G中包含创建新协程的时候,M创建了G,为了继续执行G,需要把G交给M执行,也造成了很差的局部性,因为G和G是相关的,最好放在M上执行,而不是其他M。- 系统调用 (
CPU 在 M 之间的切换) 导致频繁的线程阻塞和取消阻塞操作增加了系统开销。
2012 年之后的调度器实现原理,如下图所示:
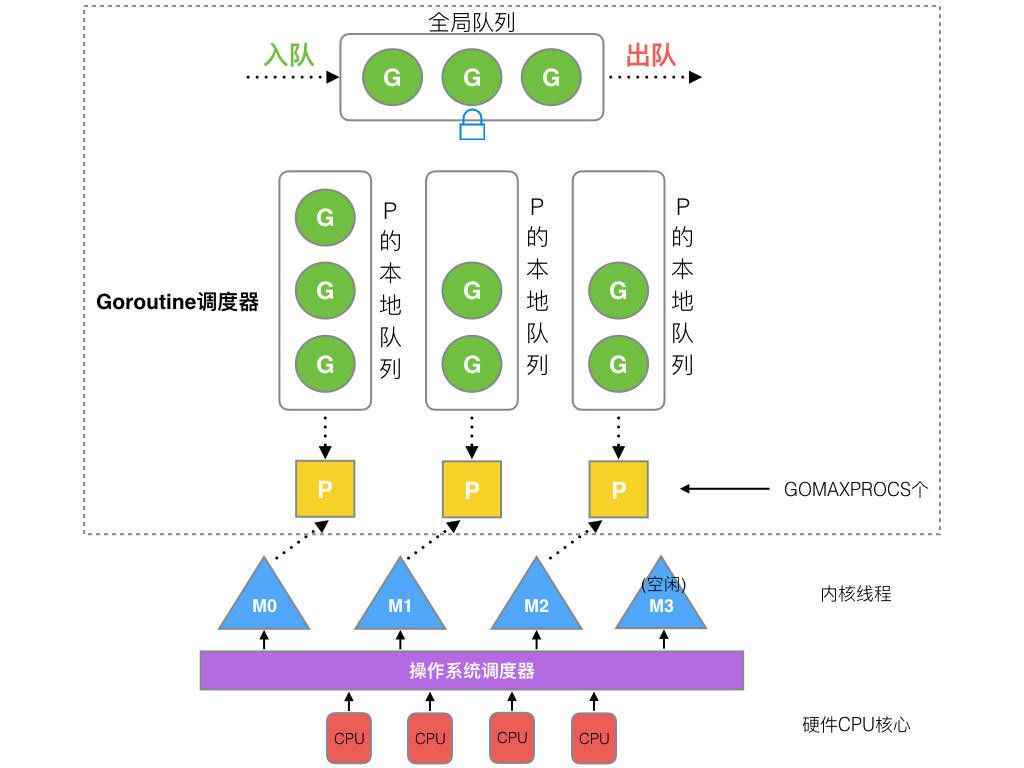
在新调度器中,除了 M (thread)和 G (goroutine),又引进了 P (Processor)。Processor,它包含了运行 goroutine 的资源,如果线程想运行 goroutine,必须先获取 P,P 中还包含了可运行的 G 队列。
在 Go 中,线程是运行 goroutine 的实体,调度器的功能是把可运行的 goroutine 分配到工作线程上。调度过程如下:
- 全局队列(
Global Queue):存放等待运行的G。 P的本地队列:同全局队列类似,存放的也是等待运行的G,存的数量有限,不超过256个。新建G时,G优先加入到P的本地队列,如果队列满了,则会把本地队列中一半的G移动到全局队列。P列表:所有的P都在程序启动时创建,并保存在数组中,最多有GOMAXPROCS(可配置) 个。M:线程想运行任务就得获取P,从P的本地队列获取G,P队列为空时,M也会尝试从全局队列拿一批G放到P的本地队列,或从其他P的本地队列偷一半放到自己P的本地队列。M运行G,G执行之后,M会从P获取下一个G,不断重复下去。
Goroutine 调度器和 OS 调度器是通过 M 结合起来的,每个 M 都代表了 1 个内核线程,OS 调度器负责把内核线程分配到 CPU 的核上执行。
调度器设计策略
复用线程: 避免频繁的创建、销毁线程,而是对线程的复用。
work stealing机制
当本线程无可运行的 G 时,尝试从其他线程绑定的 P 偷取 G,而不是销毁线程。
hand off机制
当本线程因为 G 进行系统调用阻塞时,线程释放绑定的 P,把 P 转移给其他空闲的线程执行。
- 利用并行:
GOMAXPROCS设置P的数量,最多有GOMAXPROCS个线程分布在多个CPU上同时运行。GOMAXPROCS也限制了并发的程度,比如GOMAXPROCS = 核数/2,则最多利用了一半的CPU核进行并行。 - 抢占:在
coroutine中要等待一个协程主动让出CPU才执行下一个协程,在Go中,一个goroutine最多占用CPU10ms,防止其他goroutine被饿死,这就是goroutine不同于coroutine的一个地方。 - 全局
G队列:在新的调度器中依然有全局G队列,但功能已经被弱化了,当M执行work stealing从其他P偷不到G时,它可以从全局G队列获取G。
go func () 调度流程
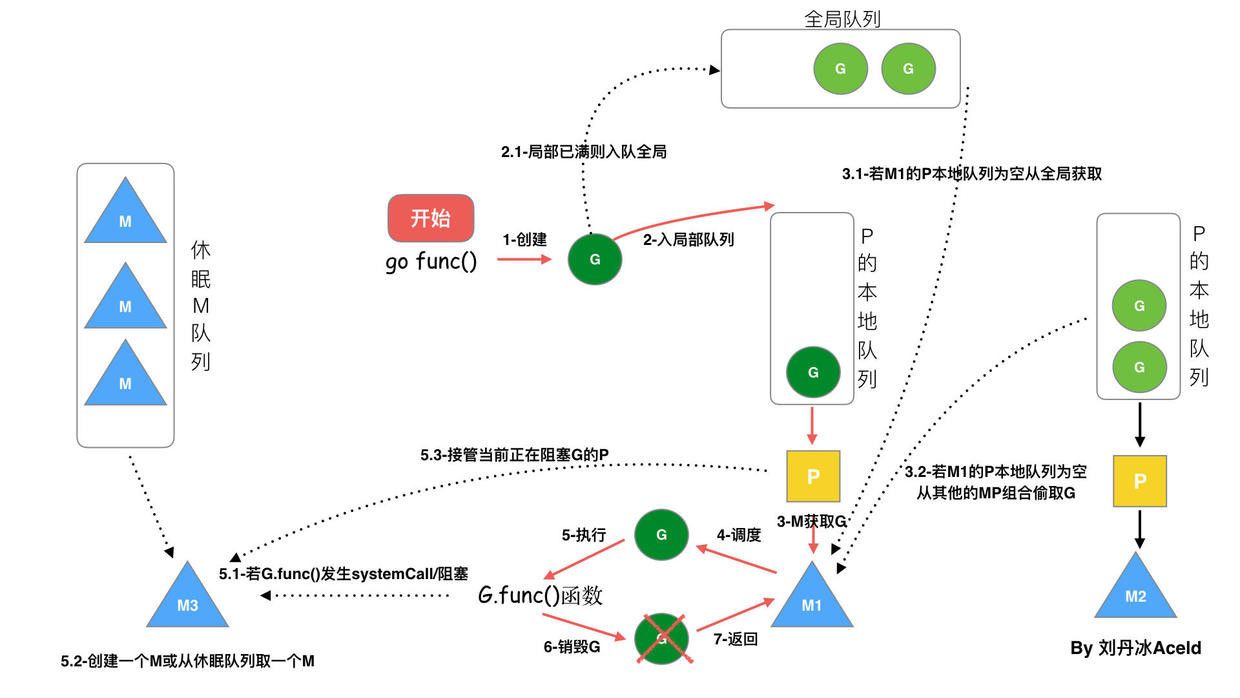
流程如下:
- 通过
go func ()来创建一个goroutine - 有两个存储
G的队列,一个是局部调度器P的本地队列、一个是全局G队列。新创建的G会先保存在P的本地队列中,如果P的本地队列已经满了就会保存在全局的队列中; G只能运行在M中,一个M必须持有一个P,M与P是1:1的关系。M会从P的本地队列弹出一个可执行状态的G来执行,如果P的本地队列为空,就会向其他的MP组合偷取一个可执行的G来执行;- 一个
M调度G执行的过程是一个循环机制; - 当
M执行某一个G时候如果发生了syscall或则其余阻塞操作,M会阻塞,如果当前有一些G在执行,runtime会把这个线程M从P中摘除 (detach),然后再创建一个新的操作系统的线程 (如果有空闲的线程可用就复用空闲线程) 来服务于这个P; - 当
M系统调用结束时候,这个G会尝试获取一个空闲的P执行,并放入到这个P的本地队列。如果获取不到P,那么这个线程M变成休眠状态, 加入到空闲线程中,然后这个G会被放入全局队列中。
调度器的生命周期
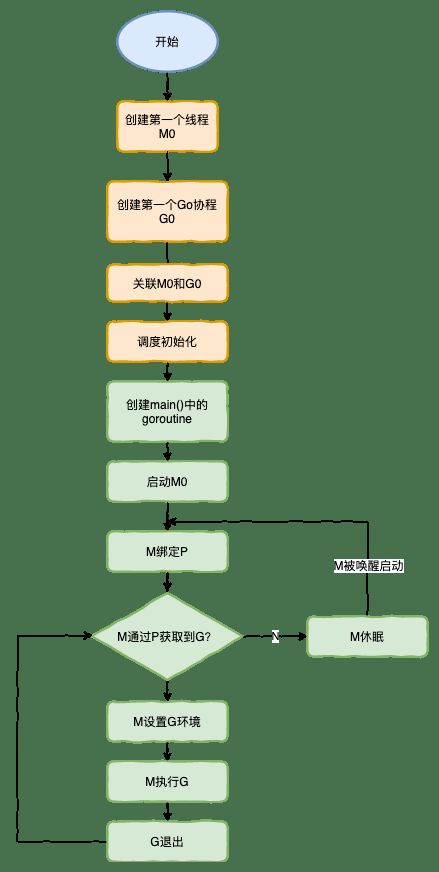
特殊的 M0 和 G0
M0
M0 是启动程序后的编号为 0 的主线程,这个 M 对应的实例会在全局变量 runtime.m0 中,不需要在 heap 上分配,M0 负责执行初始化操作和启动第一个 G, 在之后 M0 就和其他的 M 一样了。
G0
G0 是每次启动一个 M 都会第一个创建的 goroutine,G0 仅用于负责调度的 G,G0 不指向任何可执行的函数,每个 M 都会有一个自己的 G0。在调度或系统调用时会使用 G0 的栈空间,全局变量的 G0 是 M0 的 G0。
我们来跟踪一段代码:
package main
import "fmt"
func main() {
fmt.Println("Hello world")
}
接下来我们来针对上面的代码对调度器里面的结构做一个分析,也会经历如上图所示的过程:
runtime创建最初的线程m0和goroutine g0,并把2者关联。- 调度器初始化:初始化
m0、栈、垃圾回收,以及创建和初始化由GOMAXPROCS个P构成的P列表。 - 示例代码中的
main函数是main.main,runtime中也有1个main函数 ——runtime.main,代码经过编译后,runtime.main会调用main.main,程序启动时会为runtime.main创建goroutine,称它为main goroutine吧,然后把main goroutine加入到P的本地队列。 - 启动
m0,m0已经绑定了P,会从P的本地队列获取G,获取到main goroutine。 G拥有栈,M根据G中的栈信息和调度信息设置运行环境。M运行G。G退出,再次回到M获取可运行的G,这样重复下去,直到main.main退出,runtime.main执行Defer和Panic处理,或调用runtime.exit退出程序。
调度器的生命周期几乎占满了一个 Go 程序的一生,runtime.main 的 goroutine 执行之前都是为调度器做准备工作,runtime.main 的 goroutine 运行,才是调度器的真正开始,直到 runtime.main 结束而结束。
转载请注明来源:janrs.com/mffp