简单原理:使用 ChatGPT enbedding,对现有的数据文档,将文本转换为向量,进行矢量化处理,并存入Redis向量数据库,实现向量相似度搜索。新的提问过来,先使用 ChatGPT enbedding 处理一次,然后根据Redis向量数据库提供的相似性搜索,找到匹配的答案。
ChatGPT Embeddings是什么?
Embeddings是一种将文本转换为数值向量的技术,它可以让计算机更好地理解和处理自然语言。Embeddings可以将每个单词或者每个句子映射到一个高维空间中的一个点,这个点的坐标就是该单词或句子的向量。
Embeddings可以保留文本中的语义、语法和情感信息,使得具有相似含义或相似用法的单词或句子在空间中距离较近,而具有不同含义或不同用法的单词或句子在空间中距离较远,从而生成更加丰富和准确的向量。
ChatGPT Embeddings指的是通过使用ChatGPT或类似的语言模型生成的数值化表示,这些表示捕捉了文本数据的语义信息。Embeddings是高维空间中的向量,它们将文本转换为一系列数值,这些数值可以用于比较文本之间的相似度、作为机器学习模型的输入特征,或用于其他自然语言处理任务。
在机器学习和自然语言处理中,将词、短语、句子或整个文档转换为向量的过程称为“嵌入”(embedding)。这些嵌入向量通常通过训练大型神经网络模型(如GPT系列、BERT、Word2Vec等)在大量文本数据上获得,以便捕获语言的深层语义和句法特征。
例如,使用ChatGPT模型,您可以输入一个句子或段落,模型将输出一个固定长度的向量,这个向量数值上表示了输入文本的内容。然后,这些嵌入向量可以用于各种应用,比如通过计算两个向量之间的距离来找到语义上相似的文本。
示例请求
curl https://api.openai.com/v1/embeddings \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"input": "The food was delicious and the waiter...",
"model": "text-embedding-ada-002",
"encoding_format": "float"
}'
响应
{
"object": "list",
"data": [
{
"object": "embedding",
"embedding": [
0.0023064255,
-0.009327292,
.... (1536 floats total for ada-002)
-0.0028842222,
],
"index": 0
}
],
"model": "text-embedding-ada-002",
"usage": {
"prompt_tokens": 8,
"total_tokens": 8
}
}
- 文档地址 https://platform.openai.com/docs/api-reference/embeddings/create
- 官网示例 https://github.com/openai/openai-cookbook/
Redis向量数据库是什么?
Redis 向量数据库是一种专门为向量数据存储和检索而设计的数据库。它基于 Redis 的内存数据库,具有高性能和可扩展性,非常适合存储和查询高维向量数据。
向量数据是一种由多个数值组成的多维数据结构,广泛应用于机器学习、自然语言处理、图像处理等领域。传统的关系型数据库不擅长存储和处理向量数据,而 Redis 向量数据库则专为处理向量数据而设计,具有以下特点:
- 高性能: Redis 向量数据库采用内存数据库作为存储引擎,具有极高的读写性能,可以满足实时查询和分析的需求。
- 可扩展性: Redis 向量数据库支持水平扩展,可以轻松地通过添加更多的节点来提高数据库的吞吐量和容量。
- 易于使用: Redis 向量数据库提供了友好的 API,可以轻松地将向量数据存储、查询和检索。
Redis 向量数据库的一些典型应用场景包括:
- 文本相似度分析: 将文本编码成向量,然后使用向量相似度来衡量文本之间的相似性。
- 图像相似度搜索: 将图像编码成向量,然后使用向量相似度来搜索与查询图像相似的图像。
- 推荐系统: 将用户和物品编码成向量,然后使用向量相似度来推荐用户可能感兴趣的物品。
- 欺诈检测: 将正常的交易和欺诈交易编码成向量,然后使用向量相似度来检测欺诈交易。
如果您需要存储和处理向量数据,那么 Redis 向量数据库是一个非常好的选择。它具有高性能、可扩展性和易于使用的特点,可以帮助您快速构建功能强大的向量数据应用程序。
PHP 代码实现
按照之前编写需要RedisSearch 和 RedisJSON 两个扩展模块支持,使 Redis 得以支持结构化数据的搜索。
注意:该依赖包需要PHP版本PHP >=8.1。可以通过php -v查看是否符合版本要求
/var/www/webman-admin # php -v
PHP 8.2.10 (cli) (built: Sep 2 2023 07:09:39) (NTS)
Copyright (c) The PHP Group
Zend Engine v4.2.10, Copyright (c) Zend Technologies
with Zend OPcache v8.2.10, Copyright (c), by Zend Technologies
composer 安装扩展包
composer require openai-php/client
安装过程
Chat 测试
$apiKey = 'xxxxxxxxxxxxxxxxxx';
$client = \OpenAI::factory()
->withApiKey($apiKey)
->withBaseUri('api.openai.com/v1')
->withHttpClient($client = new \GuzzleHttp\Client([]))
->withStreamHandler(fn(\Psr\Http\Message\RequestInterface $request): \Psr\Http\Message\ResponseInterface => $client->send($request, [
'stream' => true // Allows to provide a custom stream handler for the http client.
]))->make();
$result = $client->chat()->create([
'model' => 'gpt-3.5-turbo-0613',
'messages' => [
['role' => 'user', 'content' => 'Tinywan 程序员是谁?'],
],
]);
echo '[开源技术小栈响应]:'.$result->choices[0]->message->content;
return response_json(0,'success');
请求访问地址:http://127.0.0.1:8201/test/openai。以上会话打印以下内容表示SDK没问题

更多了解:https://platform.openai.com/docs/api-reference/chat/create
Embeddings 使用
$apiKey = 'xxxxxxxxxxxxxxxxxx';
$client = \OpenAI::factory()
->withApiKey($apiKey)
->withBaseUri('api.openai.com/v1')
->withHttpClient($client = new \GuzzleHttp\Client([]))
->withStreamHandler(fn(\Psr\Http\Message\RequestInterface $request): \Psr\Http\Message\ResponseInterface => $client->send($request, [
'stream' => true // Allows to provide a custom stream handler for the http client.
]))->make();
/** TODO 1、利用ChatGTP Embeddings功能,将文本转换为向量 */
$input = 'Hi,我是Tinywan,开源技术小栈公众号作者。一只程序猿,毕业于二流院校,目前在杭州工作。';
$response = $client->embeddings()->create([
'model' => 'text-embedding-ada-002',
'input' => $input,
'encodding_format' => 'float' // 向量是一组多维的数组,数组元素为 float 类型数据。
]);
/** TODO 2、将文本向量并存储到Redis中,实现向量相似度搜索 */
$textEmbeddingVector = $response['data'][0]['embedding'];
$indexName = 'tinywan:embedding:2024';
try {
$indexExist = Redis::rawCommand('FT.INFO', $indexName);
} catch (\Throwable $e) {
$indexExist = false;
}
/** TODO 3、索引不存在,创建索引 */
if(!$indexExist) {
Redis::rawCommand('FT.CREATE', $indexName, 'on', 'JSON', 'PREFIX', '1', "$indexName:", 'SCHEMA',
'$.text_embedding', 'AS', 'text_embedding', 'VECTOR', 'FLAT', '6', 'DIM', '1536', 'DISTANCE_METRIC', 'COSINE', 'TYPE', 'FLOAT32');
}
/** TODO 4、添加向量存储 */
$embeddingKey = 'tinywan:embedding:2024:'.time();
$embeddingValue = [
'key' => $embeddingKey,
'content' => $input,
'text_embedding' => $textEmbeddingVector
];
Redis::rawCommand('JSON.SET', $embeddingKey, '$', json_encode($embeddingValue, JSON_UNESCAPED_UNICODE));
请求访问地址:http://127.0.0.1:8201/test/openai。会打印出好多向量
这里内容比较多
[
0.01726415,
-0.024315901,
-0.010605723,
-0.02709727,
-0.018514361,
0.017460812,
-0.022475703,
0.0029130618,
-0.0068199714,
-0.008941116,
....
....
]
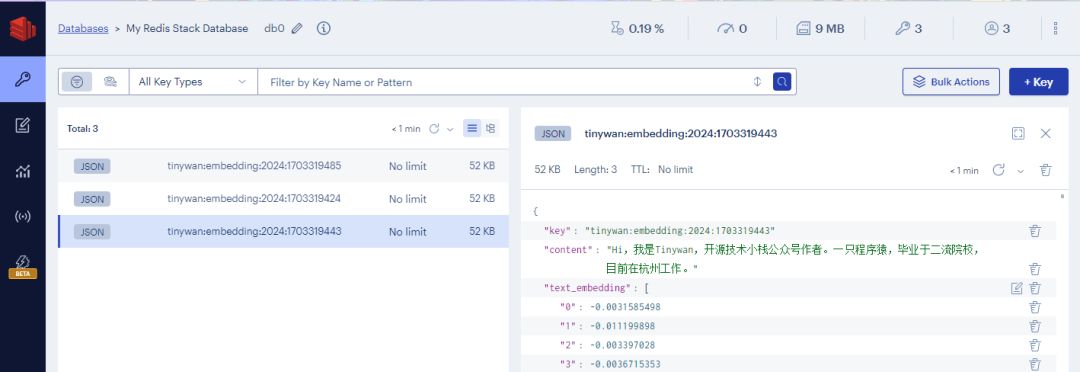
最终数据存储结果
搜索
try {
$apiKey = 'xxxxxxxxxxxxxxxxxx';
$client = \OpenAI::factory()
->withApiKey($apiKey)
->withBaseUri('api.openai.com/v1')
->withHttpClient($client = new \GuzzleHttp\Client([]))
->withStreamHandler(fn(\Psr\Http\Message\RequestInterface $request): \Psr\Http\Message\ResponseInterface => $client->send($request, [
'stream' => true // Allows to provide a custom stream handler for the http client.
]))->make();
/** TODO 1、利用ChatGTP Embeddings功能,将文本转换为向量 */
$response = $client->embeddings()->create([
'model' => 'text-embedding-ada-002',
'input' => '开源技术小栈',
'encodding_format' => 'float' // 向量是一组多维的数组,数组元素为 float 类型数据。
]);
$embedding = $response['data'][0]['embedding'];
$blob = '';
foreach ($embedding as $value) {
$blob .= pack('f', $value);
}
$indexName = 'tinywan:embedding:2024';
$count = 10;
$redisResult = Redis::rawCommand('FT.SEARCH', $indexName, '*=>[KNN ' .
$count . ' @text_embedding $blob]', 'PARAMS', '2', 'blob', $blob, 'SORTBY', '__text_embedding_score', 'DIALECT', '2');
/** TODO 2、查询向量分数最高的1条数据 */
if (!isset($redisResult[2][3])) {
return json(['content' => []]);
}
/** TODO 3、返回精准查询内容 */
$resultArr = json_decode($redisResult[2][3], true);
} catch (\Throwable $throwable) {
var_dump('异常错误 ' . $throwable->getMessage() . '|' . $throwable->getFile() . '|' . $throwable->getLine());
return json([]);
}
return json(['content' => $resultArr['content']]);
搜索方式: 使用 KNN 搜索方式,根据给定的一段文本,搜索相似的文档
查询案例和法语
127.0.0.1:6379> FT.SEARCH books-idx "*=>[KNN 10 @title_embedding $query_vec AS title_score]" PARAMS 2 query_vec <"Planet Earth" embedding BLOB> SORTBY title_score DIALECT 2
查询结果
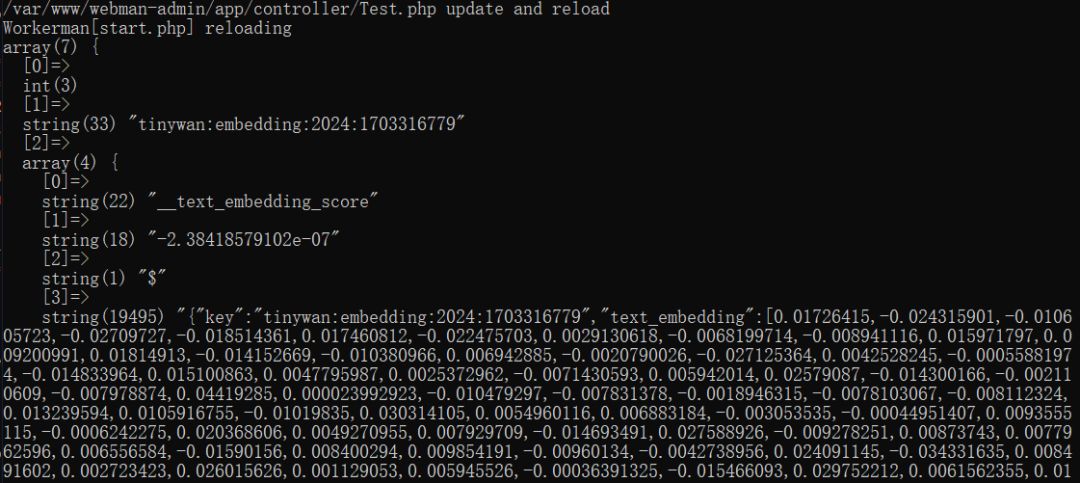

搜索程序猿,程序猿就被精准的排在第一位啦!

本文使用 ChatGPT Embeddings 的向量化处理,Redis JSON 和搜索功能,演示了如何实现一个简单的文本相似性搜索。