目录
- 索引是什么?
- 索引的结构?
- 索引存在哪儿?
- 索引的优缺点?
- 索引的分类
- 索引使用
- explain执行计划
- 索引使用规范(索引失效分析)
- 例子总结:
索引是什么?
- 索引是帮助MySQL进行高效查询的一种数据结构。好比一本书的目录,能加快查询的速度
索引的结构?
索引可以有B-Tree索引,Hash索引。索引是在存储引擎中实现的
InnoDB / MyISAM 仅支持 B-Tree索引
Memory/Heap 支持B-Tree索引和Hash索引
- B-Tree
- B-Tree是一种非常适合用于磁盘操作的数据结构。它是一棵多路平衡查找树。其高度一般在2-4,其非叶子节点,叶子节点,都会存储数据。其所有的叶子节点,都在同一层。下图是一颗B-Tree
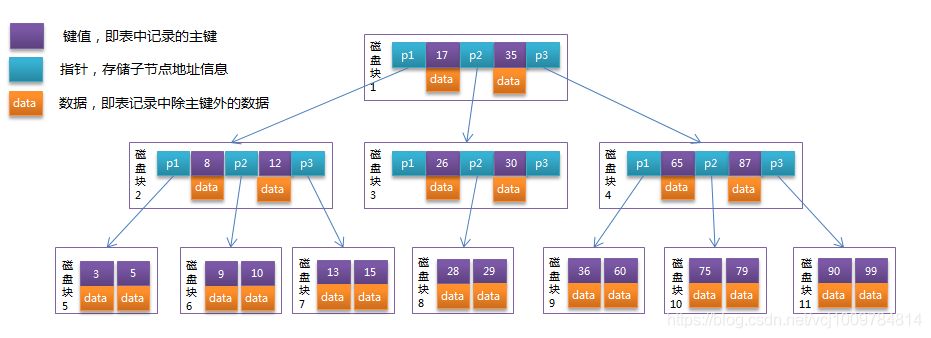
- B+ Tree:B+树是在B-Tree基础上的一种优化。它和B树的主要区别在于:B+树的数据全部存储在叶子节点中,且叶子节点被一个链表串了起来。下图是一颗B+树
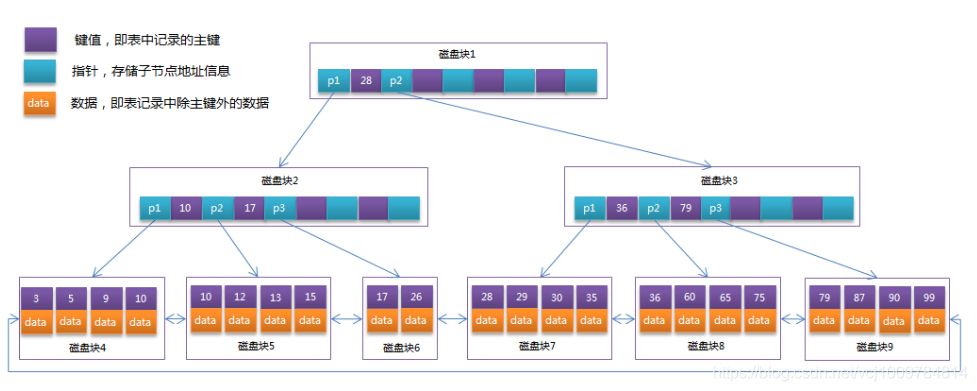
InnoDB中一个页的大小为16KB(一个页即B+树上的一个节点),若表的主键为INT,大小为4字节,那一个节点也能够存储4K个键值,假设指针和键值都占相同大小,那么高度为3的B+树,第二层有2048个节点,第三层的叶子节点数为2048*2048 = 4194304,一个节点为16KB,则一共可容纳67108864KB,即65536MB,即64G的数据。
由于叶子节点是被一个链表串起来的,所以若order by 索引列,则默认已经是排好序的,所以效率会很高。
- MyISAM索引
- MyISAM的索引和数据是分开存放的。在MyISAM的主键索引中,B+树叶子节点里,存的是记录的地址,故MyISAM通过索引查询,需要经过2次IO
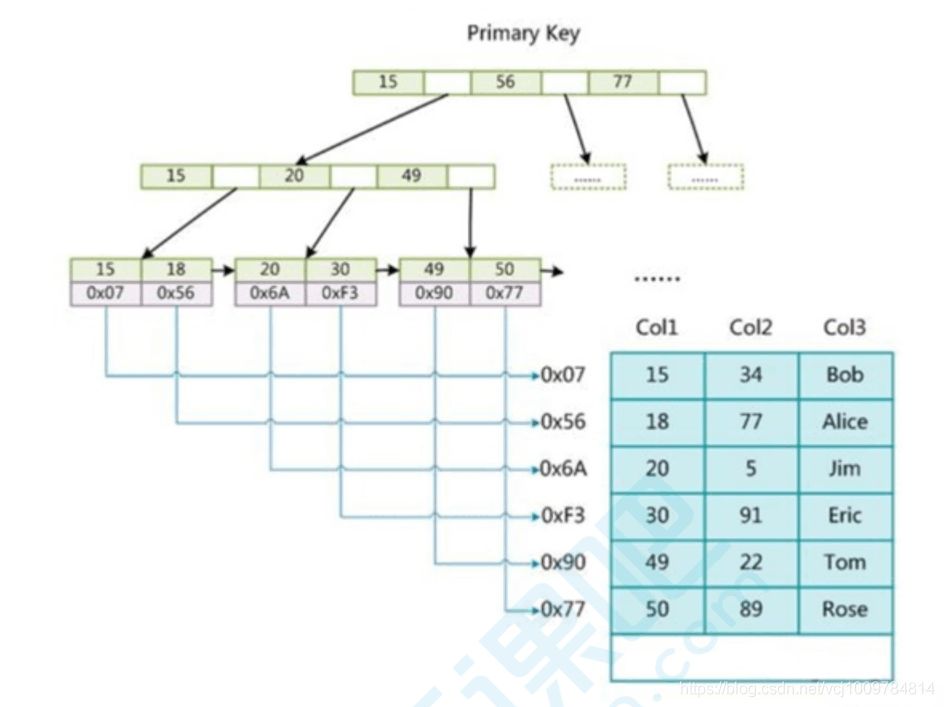
MyISAM的辅助索引和主键索引一样,唯一的区别是,辅助索引中的key可以重复,而主键索引的key不能重复
- InnoDB索引
- InnoDB的数据和索引是存放在一起的,又称聚集索引。数据通过主键索引,存放在主键索引B+树的叶子节点上。
- InnoDB主键索引,数据已经包含在了叶子节点中,即索引和数据存放在一起,是为聚集索引。
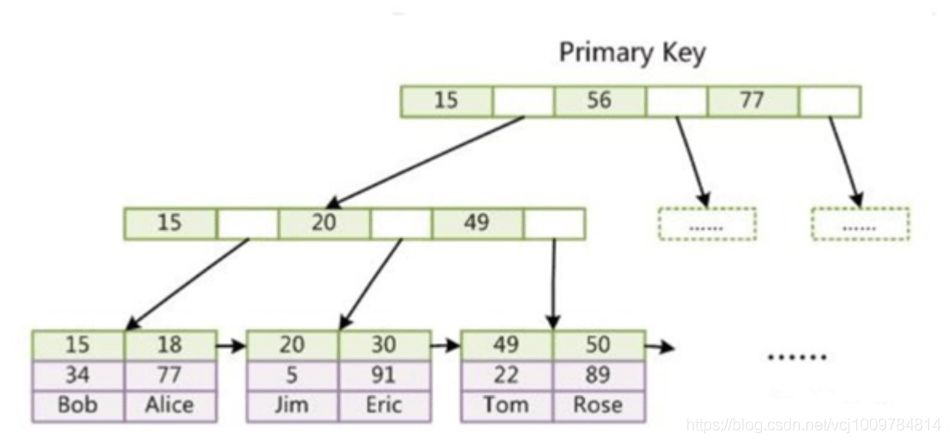
InnoDB的辅助索引,叶子节点中存的是主键值,而不是地址。走辅助索引,需要检索2次。
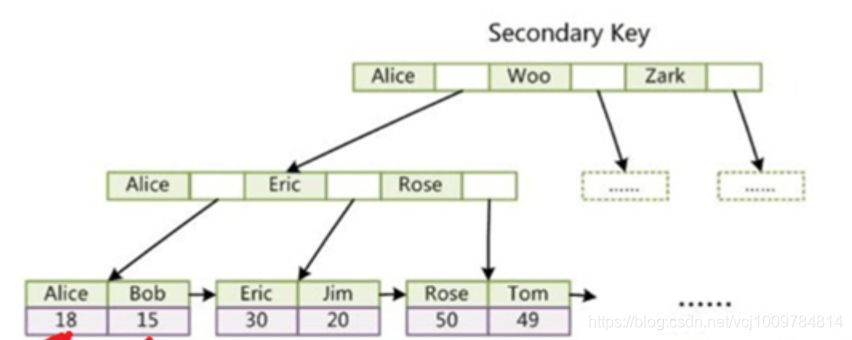
InnoDB和MyISAM索引的区别:
- InnoDB使用聚集索引,其主键索引叶子节点中直接存储了数据,而其辅助索引中叶子节点存的是主键的值
- MyISAM使用非聚集索引,数据和索引不在同一个文件中,其主键索引中叶子节点上存的是该行记录所在的地址,其辅助索引中叶子节点上存的也是记录所在的地址,只是辅助索引的key可以重复,而主键索引的key不能重复
问题:
- InnoDB为什么不要使用过长的字段做主键?
- 过长的主键,会使得辅助索引所占空间变得很大
- 为什么推荐InnoDB使用自增主键?
- 若使用自增主键,则每次插入新的记录,就会顺序的将新记录添加到当前索引节点的后续位置,一页写满了,才会进行开辟新的一页,这样使得索引结构很紧凑,且每次插入时不需要移动已有数据,非常高效。而如果不使用自增主键,则每次插入新记录时,都要选择一个插入位置,并且可能需要移动数据,使得效率不高,且索引结构不紧凑
- 为什么要用B+树,不用B树
索引存在哪儿?
- 索引本身也比较大,一般会存储在磁盘中,索引和数据可能是分开存放的(MyISAM的非聚集索引),也可能是一起存放的(InnoDB的聚集索引)
索引的优缺点?
- 优点
- 降低IO成本,提高数据查询效率
- 降低排序成本(被索引的列会自动排序,使用order by 效率会提高很多)
- 缺点
- 索引会额外占据存储空间
- 索引会降低更新表数据的效率。进行增删改操作时,不仅要保存数据,还要更新对应的索引
索引的分类
- 单列索引
- 主键索引
- 唯一索引
- 普通索引
- 组合索引
索引使用
- 建立索引
CREATE INDEX index_name ON table_name(col_name);
-- 或者
ALTER TABLE table_name ADD INDEX index_name(col_name)
- 删除索引
DROP INDEX index_name ON table_name;
- 需要建立索引的场景
- 频繁作为查询条件的列,需建索引
- 多表关联中,关联字段需建索引
- 查询中排序的字段,需建索引
- 不适用索引的场景
- 写多读少的表,不适合建索引
- 频繁更新的字段,不适合建索引
explain执行计划
现有一张user表,其索引如下所示

其中name,age,address 三个字段作为一个组合索引
可以使用explain对某个SQL语句进行性能分析
explain select * from user where name = 'am';

possible_keys
可能用到的索引
key
实际用到的索引
key_len
用于查询的索引的长度
ref
如果是等值查询,这里会会是const
rows
预计需要扫描的行数(不是精确值)
extra
额外信息,如
- using where
- 表示存储引擎返回的结果,还需要在SQL Layer层过滤
- using index
- 表示不需要回表查询,一般在使用了覆盖索引时会是这个值。覆盖索引指的是,select中的列,全是索引列。不需要回表查询指的是,直接走辅助索引,就能拿到索引列的值,不需要再去主键索引上取记录了
- using index condition
- MySQL 5.6.x之后支持ICP特性(Index Condition Pushdown),可以把检查条件下推到存储引擎层,不符合条件的记录,直接不读取,而不是像原来一样,先读取出来,再在SQL Layer层过滤,这样减少了存储引擎层扫描的行数

- using filesort
- 排序时无法用到索引
type
- system : 表中只有1行数据,或空表
- const : 使用唯一索引或主键索引,且用where等值查询,返回记录是1行,又叫唯一索引扫描

- ref : 针对非唯一索引,使用等值where条件,或者最左前缀规则的查询。
下面是满足了最左前缀规则,即对idx_name_age_add来说,满足了最左前缀,第一个索引为name

- range:索引范围扫描,常见于>,<,between,in,like等查询


注意like时,通配符%不能放在开头,否则会导致全表扫描

- index : 没有完全匹配上索引,但不用回表查询的


- all: 全表扫描,然后再在SQL Layer层过滤符合要求的记录
索引使用规范(索引失效分析)
- 全值匹配
- 在索引列上使用等值查询
explain select * from user where name = 'y' and age =;

2. 最左前缀
组合索引中,查询条件要从组合索引的最左列开始,如上述example中组合索引idx_name_age_add,是建立在三个列name,age,address的,若跳过name,直接用age查询,则会变为全表扫描
explain select * from user where age =;

3. 不要在索引列上做计算
4. 范围条件右侧的索引列会失效
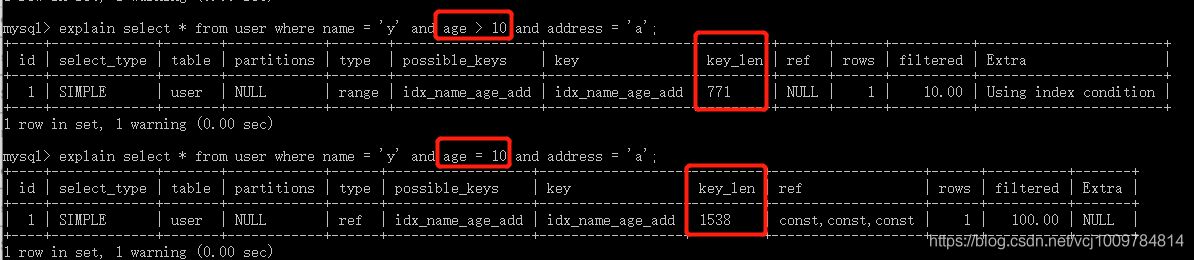
看到第一个SQL语句,没有用上addresss索引
5. 尽量使用覆盖索引
explain select name,age from user where name = 'y' and age =;
可以避免回表查询
6. 索引字段不要使用不等(!= 或 <>),不要判断null(is null/ is not null)
会导致索引失效,转为全表扫描


7. 索引字段上使用like时,不要以%开头

8. 索引字段如果是字符串,记得加单引号
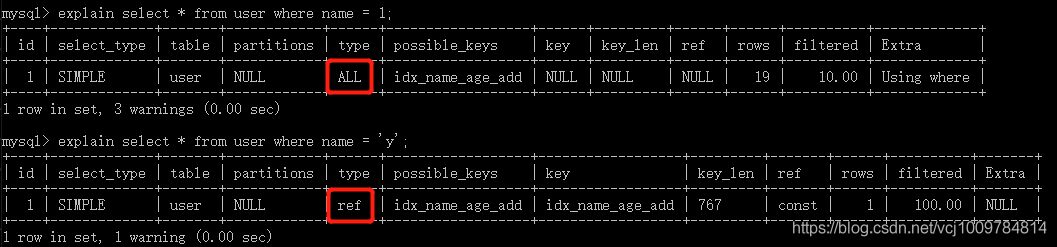
9. 索引字段不要用or

例子总结:
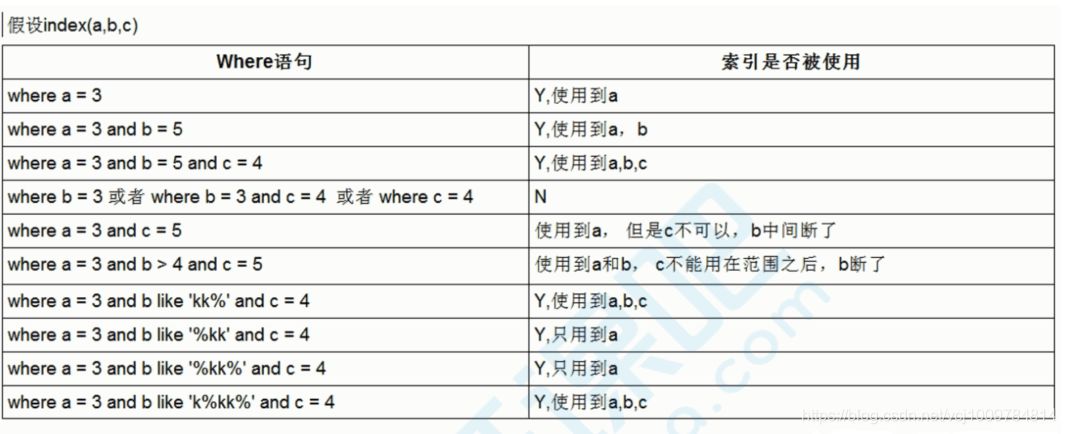
顺口溜:
全值匹配我最爱,最左前缀不放开。
带头大哥不能死,中间兄弟不能断。
索引列上不计算,范围查询后全断。
like百分号写最右,覆盖索引搞起来。
不等空值以及or,索引通通说拜拜。