Kubernetes集群监控-使用Alertmanager报警配置
王先森2024-01-032024-01-03
Alertmanager简介
Prometheus 架构中采集数据和发送告警是独立出来的, 告警触发后将信息转发到独立的组件 Alertmanager,满足告警触发条件就会向 Alertmanager 发送告警信息,最后通过接收器 recevier 发送给指定用户。
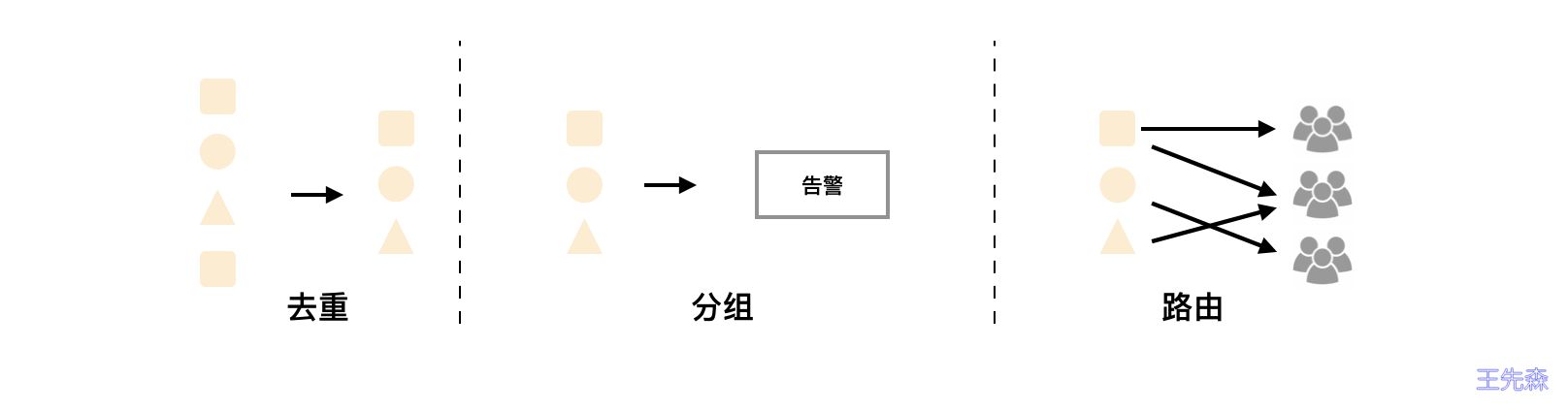
工作机制
Alertmanager 收到告警信息后:
- 进行分组
Group(告警组) - 通过定义好的路由
routing转发到正确的接收器recevier recevier通过emaildingtalkwechat等方式通知给定义好的接收人
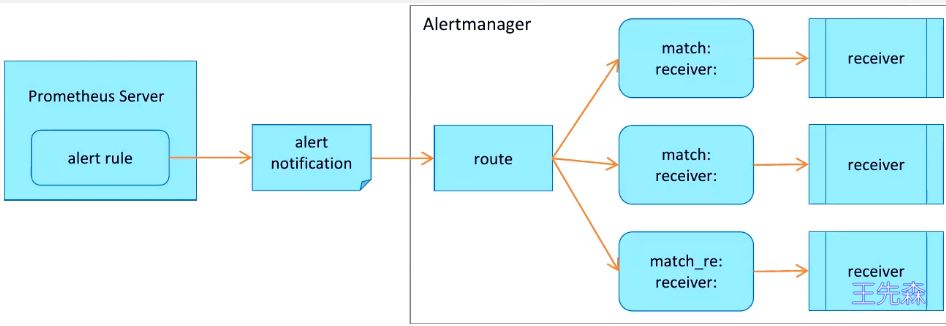
四大功能
- 分组 (Grouping): 将同类型的告警进行分组, 合并多条告警到一个通知中
- 抑制 (Inhibition): 当某条告警已经发送, 停止重复发送由此告警引起的其他异常或者故障
- 静默 (Silences): 根据标签快速对告警进行静默处理, 如果告警符合静默的配置, Alertmanager 则不会发送告警通知
- 路由 (Route): 用于配置 Alertmanager 如何处理传入的特定类型的告警通知
配置详解
global:
# 经过此时间后,如果尚未更新告警,则将告警声明为已恢复。(即 prometheus 没有向 Alertmanager 发送告警了)
resolve_timeout: 5m
# 配置发送邮件信息
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: 'wangxiansen@boysec.cn'
smtp_auth_username: 'wangxiansen@boysec.cn'
smtp_auth_password: 'password'
smtp_require_tls: false
# 读取告警通知模板的目录。
templates:
- '/etc/alertmanager/template/*.tmpl'
# 所有报警都会进入到这个根路由下,可以根据根路由下的子路由设置报警分发策略
route:
# 先解释一下分组,分组就是将多条告警信息聚合成一条发送,这样就不会收到连续的报警了。
# 将传入的告警按标签分组(标签在 prometheus 中的 rules 中定义),例如:
# 接收到的告警信息里面有许多具有 cluster=A 和 alertname=LatencyHigh 的标签,这些个告警将被分为一个组。
#
# 如果不想使用分组,可以这样写group_by: [...]
group_by: ['alertname', 'cluster', 'service']
# 第一组告警发送通知需要等待的时间,这种方式可以确保有足够的时间为同一分组获取多个告警,然后一起触发这个告警信息。
group_wait: 30s
# 发送第一个告警后,等待"group_interval"发送一组新告警。
group_interval: 5m
# 分组内发送相同告警的时间间隔。这里的配置是每3小时发送告警到分组中。举个例子:收到告警后,一个分组被创建,等待5分钟发送组内告警,如果后续组内的告警信息相同,这些告警会在3小时后发送,但是3小时内这些告警不会被发送。
repeat_interval: 3h
# 这里先说一下,告警发送是需要指定接收器的,接收器在receivers中配置,接收器可以是email、webhook、pagerduty、wechat等等。一个接收器可以有多种发送方式。
# 指定默认的接收器
receiver: team-X-mails
# 下面配置的是子路由,子路由的属性继承于根路由(即上面的配置),在子路由中可以覆盖根路由的配置
# 下面是子路由的配置
routes:
# 使用正则的方式匹配告警标签
- match_re:
# 这里可以匹配出标签含有 service=foo1 或 service=foo2 或 service=baz 的告警
service: ^(foo1|foo2|baz)$
# 指定接收器为 team-X-mails
receiver: team-X-mails
# 这里配置的是子路由的子路由,当满足父路由的的匹配时,这条子路由会进一步匹配出 severity=critical 的告警,并使用 team-X-pager 接收器发送告警,没有匹配到的告警会由父路由进行处理。
routes:
- match:
severity: critical
receiver: team-X-pager
# 这里也是一条子路由,会匹配出标签含有 service=files 的告警,并使用 team-Y-mails 接收器发送告警
- match:
service: files
receiver: team-Y-mails
# 这里配置的是子路由的子路由,当满足父路由的的匹配时,这条子路由会进一步匹配出 severity=critical 的告警,并使用 team-Y-pager 接收器发送告警,没有匹配到的会由父路由进行处理。
routes:
- match:
severity: critical
receiver: team-Y-pager
# 该路由处理来自数据库服务的所有警报。如果没有团队来处理,则默认为数据库团队。
- match:
# 首先匹配标签service=database
service: database
# 指定接收器
receiver: team-DB-pager
# 根据受影响的数据库对告警进行分组
group_by: [alertname, cluster, database]
routes:
- match:
owner: team-X
receiver: team-X-pager
# 告警是否继续匹配后续的同级路由节点,默认false,下面如果也可以匹配成功,会向两种接收器都发送告警信息(猜测。。。)
continue: true
- match:
owner: team-Y
receiver: team-Y-pager
# 下面是关于inhibit(抑制)的配置,先说一下抑制是什么:抑制规则允许在另一个警报正在触发的情况下使一组告警静音。其实可以理解为告警依赖。比如一台数据库服务器掉电了,会导致db监控告警、网络告警等等,可以配置抑制规则如果服务器本身down了,那么其他的报警就不会被发送出来。
inhibit_rules:
#下面配置的含义:当有多条告警在告警组里时,并且他们的标签alertname,cluster,service都相等,如果severity: 'critical'的告警产生了,那么就会抑制severity: 'warning'的告警。
- source_match: # 源告警(我理解是根据这个报警来抑制target_match中匹配的告警)
severity: 'critical' # 标签匹配满足severity=critical的告警作为源告警
target_match: # 目标告警(被抑制的告警)
severity: 'warning' # 告警必须满足标签匹配severity=warning才会被抑制。
equal: ['alertname', 'cluster', 'service'] # 必须在源告警和目标告警中具有相等值的标签才能使抑制生效。(即源告警和目标告警中这三个标签的值相等'alertname', 'cluster', 'service')
# 下面配置的是接收器
receivers:
# 接收器的名称、通过邮件的方式发送、
- name: 'team-X-mails'
email_configs:
# 发送给哪些人
- to: 'team-X+alerts@example.org'
# 是否通知已解决的警报
send_resolved: true
# 接收器的名称、通过邮件和pagerduty的方式发送、发送给哪些人,指定pagerduty的service_key
- name: 'team-X-pager'
email_configs:
- to: 'team-X+alerts-critical@example.org'
pagerduty_configs:
- service_key: <team-X-key>
# 接收器的名称、通过邮件的方式发送、发送给哪些人
- name: 'team-Y-mails'
email_configs:
- to: 'team-Y+alerts@example.org'
# 接收器的名称、通过pagerduty的方式发送、指定pagerduty的service_key
- name: 'team-Y-pager'
pagerduty_configs:
- service_key: <team-Y-key>
# 一个接收器配置多种发送方式
- name: 'ops'
webhook_configs:
- url: 'http://prometheus-webhook-dingtalk.kube-ops.svc.cluster.local:8060/dingtalk/webhook1/send'
send_resolved: true
email_configs:
- to: 'wangxiansen@boysec.cn'
send_resolved: true
- to: 'admin@boysec.cn'
send_resolved: true
Alertmanager CRD
Prometheus Operator 为 Alertmanager 抽象了两个 CRD 资源:
AlertmanagerCRD: 基于 statefulset, 实现 Alertmanager 的部署以及扩容缩容AlertmanagerconfigCRD: 实现模块化修改 Alertmanager 的配置
通过 alertManager CRD 部署的实例配置文件由 secret/alertmanager-main-generated 提供
$ kubectl get pod alertmanager-main-0 -n monitoring -o jsonpath='{.spec.volumes[?(@.name=="config-volume")]}' | python -m json.tool
{
"name": "config-volume",
"secret": {
"defaultMode": 420,
"secretName": "alertmanager-main-generated"
}
}
$ kubectl get secret alertmanager-main-generated -n monitoring -o jsonpath='{.data.alertmanager\.yaml}' | base64 --decode
"global":
"resolve_timeout": "5m"
"inhibit_rules":
- "equal":
- "namespace"
- "alertname"
"source_matchers":
......
secret Alertmanager-main-generated 是自动生成的, 基于 secret Alertmanager-main 和 CRD AlertmanagerConfig
$ kubectl explain alertmanager.spec.configSecret
DESCRIPTION:
ConfigSecret is the name of a Kubernetes Secret in the same namespace as
the Alertmanager object, which contains configuration for this Alertmanager
instance. Defaults to 'alertmanager-<alertmanager-name>' The secret is
mounted into /etc/alertmanager/config.
综上, 修改 Alertmanager 配置可以修改 secret Alertmanager-main 或者 CRD Alertmanagerconfig
告警规则
prometheus 支持两种类型的规则, 记录规则 Recording Rule 和告警规则 Alerting Rule
Recording Rule
记录规则: 允许预先计算经常需要或计算量大的表达式,并将其结果保存为一组新的时间序列。查询预先计算的结果通常比每次需要时都执行原始表达式要快得多。这对于每次刷新时都需要重复查询相同表达式的仪表板特别有用。
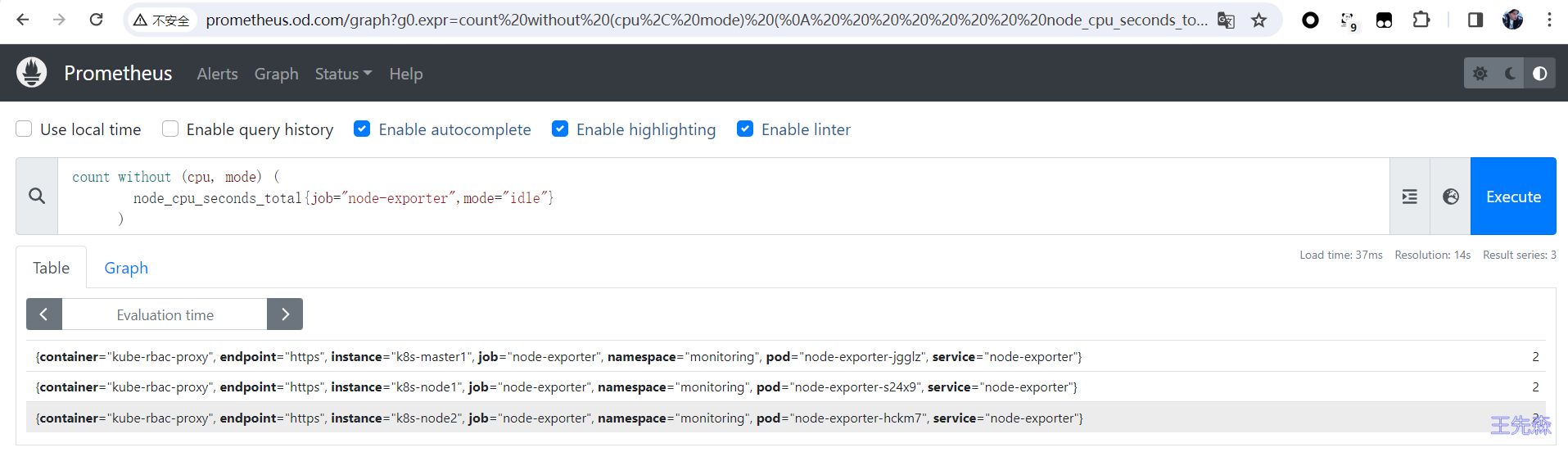
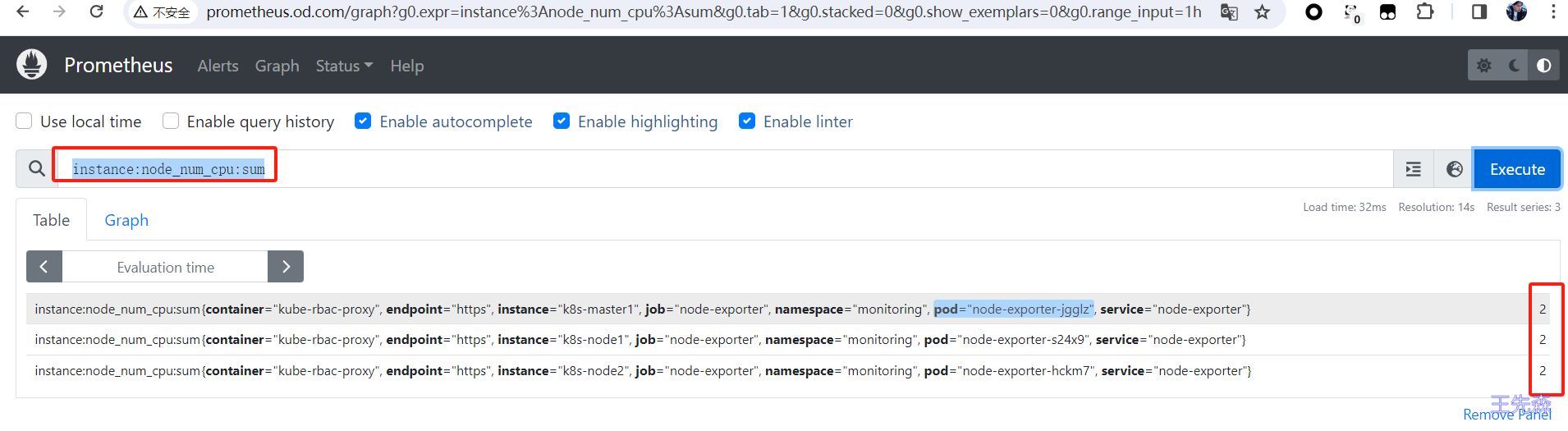
如下示例, 将统计 cpu 个数的表达式存为一个新的时间序列 instance:node_num_cpu:sum
groups:
- name: node-exporter.rules
rules:
- record: instance:node_num_cpu:sum
expr: |
count without (cpu, mode) (
node_cpu_seconds_total{job="node-exporter",mode="idle"}
)
原始表达式结果
新表达式结果
Alerting Rule
告警规则:当满足指定的触发条件时发送告警
- alert:告警规则的名称
- expr:告警触发条件, 基于 PromQL 表达式, 如果表达式执行结果为 True 则推送告警
- for:等待评估时间, 可选参数. 表示当触发条件持续一定时间后才发送告警, 在等待期间告警的状态为 pending
- labels:自定义标签
- annotaions:指定一组附加信息, 可以使用 labels externalLabels value 格式化信息. labels 储存报警实例的时序数据; externalLabels 储存 prometheus 中 global.external_labels 配置的标签; value 保存报警实例的评估值description:详细信息summary:描述信息
如下示例, 当节点的某个文件系统剩余空间不足 10% 达到 30 分钟后将发送告警
groups:
- name: test
rules:
- alert: NodeFilesystemAlmostOutOfSpace
expr: node_filesystem_avail_bytes{job="node-exporter",fstype!=""} / node_filesystem_size_bytes{job="node-exporter",fstype!=""} * 100 < 10
for: 30m
labels:
severity: warning
annotations:
description: ' {{ $labels.instance }} 节点 {{ $labels.device }} 文件系统剩余空间: {{ printf "%.2f" $value }}% '
summary: '文件系统剩余空间不足 10%'
prometheusrule CRD
Prometheus Operator 抽象出来一个 prometheusrule CRD 资源, 通过管理这个 CRD 资源实现告警规则的统一管理
kube-prometheus 默认帮我们创建了一些告警规则
kubectl get prometheusrule -A
NAMESPACE NAME AGE
monitoring alertmanager-main-rules 9d
monitoring grafana-rules 9d
monitoring kube-prometheus-rules 9d
monitoring kube-state-metrics-rules 9d
monitoring kubernetes-monitoring-rules 9d
monitoring node-exporter-rules 9d
monitoring prometheus-k8s-prometheus-rules 9d
monitoring prometheus-operator-rules 9d
prometheusrule 定义一系列报警规则
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
name: demo
namespace: monitoring
spec:
groups:
- name: group1
rules:
- alert: alert1
annotations:
description: alert-1
summary: alert-1
expr: up == 0
for: 15m
labels:
severity: critical
- alert: alert2
......
- name: group2
rules:
- alert: alert3
......
对于 prometheusrule 的更新操作 (create, delete, update) 都会被 watch 到, 然后更新到统一的一个 configmap 中, 然后 prometheus 自动重载配置
每个 prometheusrule 会作为 configmap prometheus-k8s-rulefiles-0 中的一个 data , data 的命名规则为 <namespace>-<rulename>-ruleuid
$ kubectl get cm prometheus-k8s-rulefiles-0 -n monitoring
NAME DATA AGE
prometheus-k8s-rulefiles-0 7 41m
# prometheus 实例的挂载信息
$ kubectl get pod prometheus-k8s-0 -n monitoring -o jsonpath='{.spec.volumes[?(@.name=="prometheus-k8s-rulefiles-0")]}' | python -m json.tool
{
"configMap": {
"defaultMode": 420,
"name": "prometheus-k8s-rulefiles-0"
},
"name": "prometheus-k8s-rulefiles-0"
}
# prometheus 中实际的存储路径
$ kubectl exec -it prometheus-k8s-0 -n monitoring -- ls /etc/prometheus/rules/prometheus-k8s-rulefiles-0/
monitoring-alertmanager-main-rules-2cc6f1ff-1515-46a8-8afc-fed52221844a.yaml
monitoring-grafana-rules-0b3bb420-4e1e-45de-9663-1c8e1fd0e29c.yaml
monitoring-kube-prometheus-rules-70d21f0b-9f05-43a4-a96d-1a95b7296dbf.yaml
monitoring-kube-state-metrics-rules-b06c8900-f21f-4d55-adb3-0d306a9f497f.yaml
monitoring-kubernetes-monitoring-rules-93fd31ce-5610-4f57-9e4c-0463ae12baab.yaml
monitoring-node-exporter-rules-07459872-19b2-4f07-856f-56440eede2ca.yaml
monitoring-prometheus-k8s-prometheus-rules-49b38482-2ff2-4191-b273-253964336ee1.yaml
monitoring-prometheus-operator-rules-95fe6def-fafc-4fe6-8729-daa7a5821918.yaml
prometheus 的配置中定义了 rule_files 路径
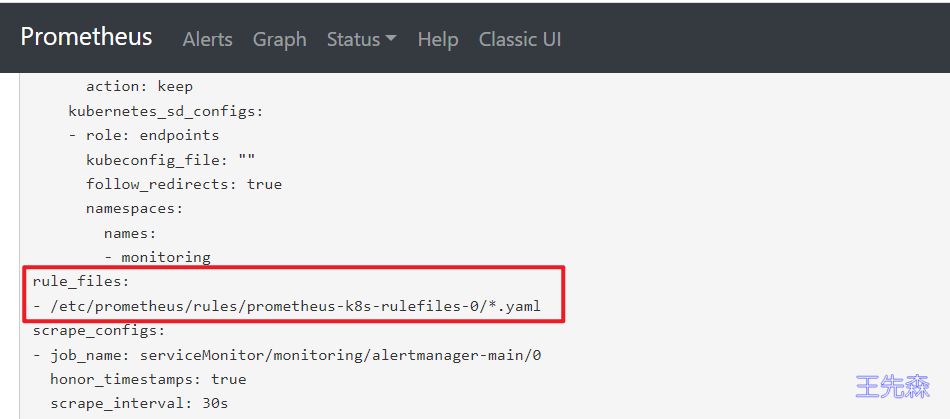
磁盘使用率报警规则
当磁盘可用空间少于 50% 时触发告警
创建 prometheusrule
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: demo
namespace: monitoring
spec:
groups:
- name: demo
rules:
- alert: nodeDiskUsage
annotations:
description: |
节点 {{$labels.instance }}
挂载目录 {{ $labels.mountpoint }}
当前可用空间 {{ printf "%.2f" $value }}%
summary: |
挂载目录可用空间低于 50%
expr: |
node_filesystem_avail_bytes{fstype!="",job="node-exporter"} /
node_filesystem_size_bytes{fstype!="",job="node-exporter"} * 100 < 50
for: 1m
labels:
severity: warning
查看生成的告警规则, 当前状态是 pending ,我们设置了 1m 的评估等待时间。一分钟过后进入 firing 状态, 正式发出告警, 此时我们设置的 $label 还没有解析。
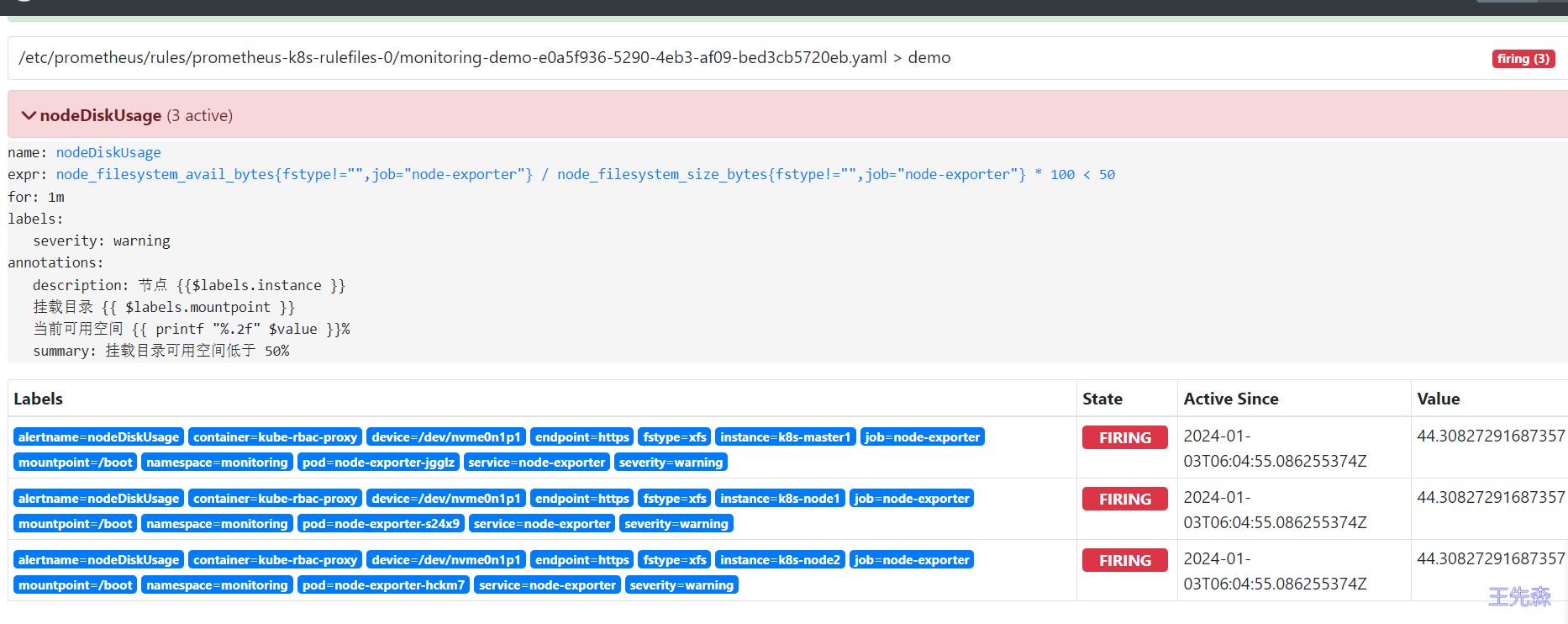
去 Alertmanager 看一下, 成功收到了告警, 且 labels 和 value 也已经正常解析了
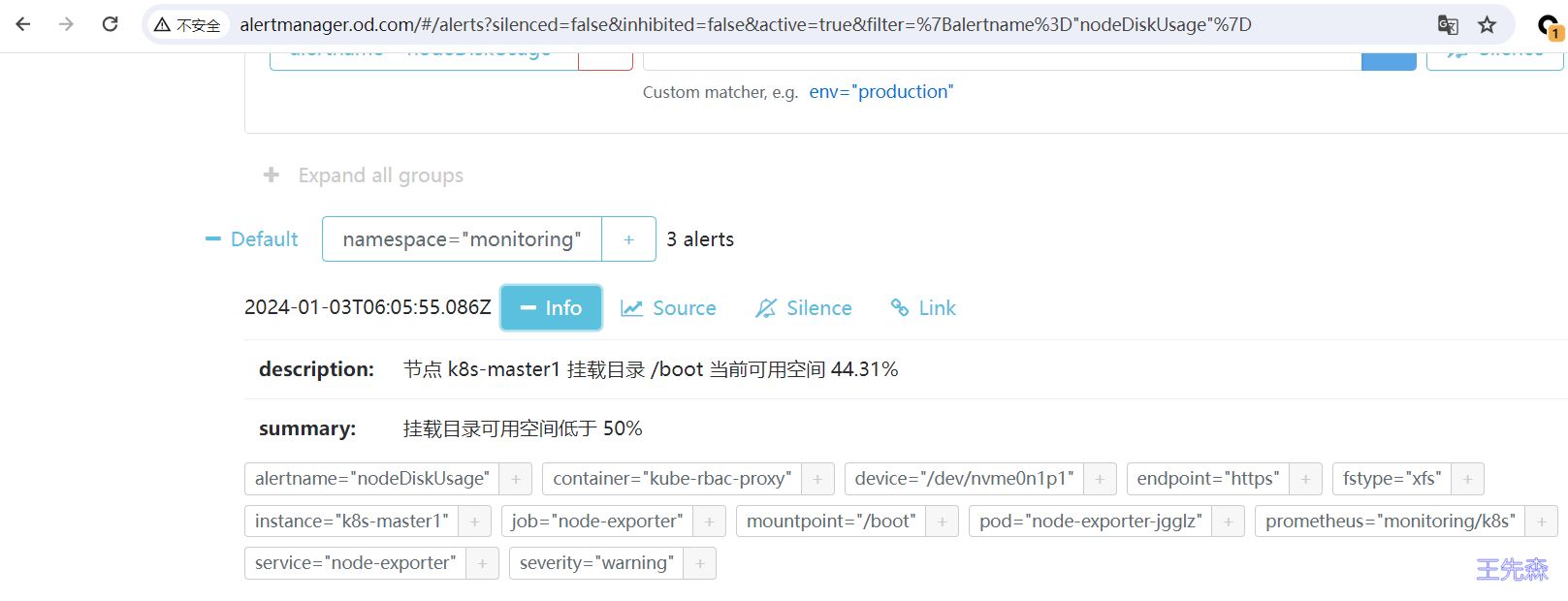
报警接收器
Alertmanager 支持很多内置的报警接收器,如 email、slack、企业微信、webhook 等。
邮件报警
修改Alertmanager配置
global:
resolve_timeout: 5m
smtp_from: 'wang_xiansen0@163.com'
smtp_smarthost: 'smtp.163.com:25'
smtp_auth_username: 'wang_xiansen0@163.com'
smtp_auth_password: 'password'
smtp_require_tls: false
smtp_hello: '163.com'
templates:
- '/etc/alertmanager/configmaps/alertmanager-templates/*.tmpl'
route:
receiver: Default
group_by: ['alertname', 'cluster']
continue: false
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
receivers:
- name: Default
email_configs:
- to: 'wangxiansen@boysec.cn'
send_resolved: true
修改 secret alertmanager-main
kubectl create secret generic alertmanager-main -n monitoring --from-file=alertmanager.yaml --dry-run=client -o yaml > alertmanager-main-secret.yaml
kubectl apply -f alertmanager-main-secret.yaml
查看生成的 secret alertmanager-main
kubectl get secret alertmanager-main -n monitoring -o jsonpath='{.data.alertmanager\.yaml}' |base64 -d
AlertmanagerConfig 配置
新建一个 AlertmanagerConfig 类型的资源对象,可以通过 kubectl explain AlertmanagerConfig 或者在线 API 文档来查看字段的含义
# vim alertmanagerconfig.yaml
apiVersion: monitoring.coreos.com/v1alpha1
kind: AlertmanagerConfig
metadata:
name: email-config
namespace: monitoring
labels:
alertmanagerConfig: wangxiansen
spec:
route:
groupBy: ['alertname']
groupWait: 30s
groupInterval: 5m
repeatInterval: 12h
receiver: 'Critical'
continue: false
routes:
- receiver: 'Critical'
match:
severity: critical
receivers:
- name: Critical
emailConfigs:
- to: 'wangxiansen@boysec.cn'
sendResolved: true
webhookConfigs:
- url: http://dingtalk
sendResolved: true
不过如果直接创建上面的配置是不会生效的,我们需要添加一个 Label 标签,并在 Alertmanager 的资源对象中通过标签来关联上面的这个对象,比如我们这里新增了一个 Label 标签:alertmanagerConfig: wangxiansen,然后需要重新更新 Alertmanager 对象,添加 alertmanagerConfigSelector 属性去匹配 AlertmanagerConfig 资源对象
# vim alertmanager-alertmanager.yaml
apiVersion: monitoring.coreos.com/v1
kind: Alertmanager
metadata:
labels:
app.kubernetes.io/component: alert-router
app.kubernetes.io/instance: main
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.26.0
name: main
namespace: monitoring
spec:
image: quay.io/prometheus/alertmanager:v0.26.0
nodeSelector:
kubernetes.io/os: linux
podMetadata:
labels:
app.kubernetes.io/component: alert-router
app.kubernetes.io/instance: main
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.26.0
replicas: 1 # 资源问题,这里就先启动一个pods
resources:
limits:
cpu: 100m
memory: 100Mi
requests:
cpu: 4m
memory: 100Mi
secrets: []
alertmanagerConfigSelector: # 匹配 AlertmanagerConfig 的标签
matchLabels:
alertmanagerConfig: wangxiansen
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: alertmanager-main
version: 0.26.0
告警模板
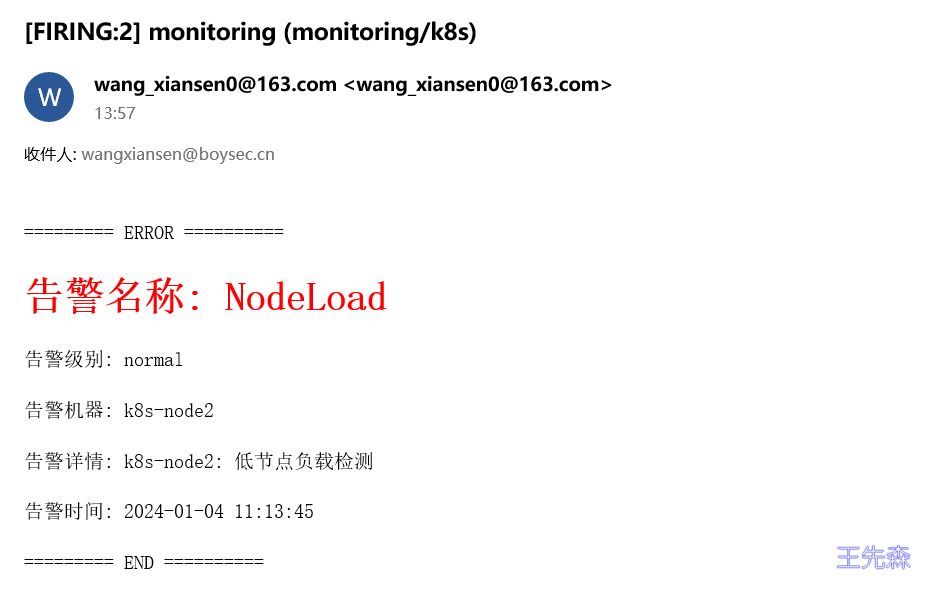
Alertmanager 收到的告警大概长这个样子
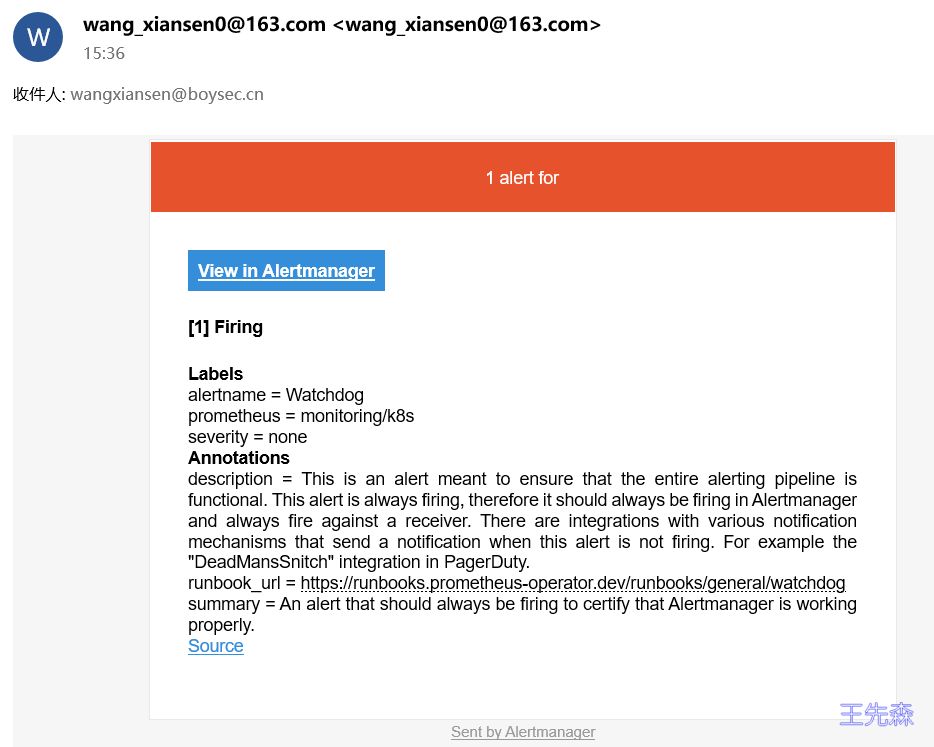
Alertmanager CRD 支持 configMaps 参数, 会自动挂载到 /etc/alertmanager/configmaps 目录, 我们可以将模板文件配置成 configmap,创建模板文件 email.tmpl
{{ define "email.html" }}
<html>
<body>
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
<p>========= ERROR ==========</p>
<h3 style="color:red;">告警名称: {{ .Labels.alertname }}</h3>
<p>告警级别: {{ .Labels.severity }}</p>
<p>告警机器: {{ .Labels.instance }} {{ .Labels.device }}</p>
<p>告警详情: {{ .Annotations.summary }}</p>
<p>告警时间: {{ time (unixMillis .StartsAt) "2006-01-02 15:04:05" }}</p>
<p>========= END ==========</p>
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
<p>========= INFO ==========</p>
<h3 style="color:green;">告警名称: {{ .Labels.alertname }}</h3>
<p>告警级别: {{ .Labels.severity }}</p>
<p>告警机器: {{ .Labels.instance }}</p>
<p>告警详情: {{ .Annotations.summary }}</p>
<p>告警时间: {{ time (unixMillis .StartsAt) "2006-01-02 15:04:05" }}</p>
<p>恢复时间: {{ time (unixMillis .EndsAt) "2006-01-02 15:04:05" }}</p>
<p>========= END ==========</p>
{{- end }}
{{- end }}
</body>
</html>
{{- end }}
创建 configmap
kubectl create configmap alertmanager-templates --from-file=email.tmpl --dry-run=client -o yaml -n monitoring > alertmanager-configmap-templates.yaml
kubectl apply -f alertmanager-configmap-templates.yaml
更新 Alertmanager 示例, 添加 configmap
# vim alertmanager-alertmanager.yaml
apiVersion: monitoring.coreos.com/v1
kind: Alertmanager
metadata:
spec:
.....
alertmanagerConfigSelector:
matchLabels:
alertmanager: main
configMaps:
- alertmanager-templates
修改 AlertmanagerConfig 配置文件, 指定模板文件
apiVersion: monitoring.coreos.com/v1alpha1
kind: AlertmanagerConfig
metadata:
name: email-config
namespace: monitoring
labels:
alertmanagerConfig: wangxiansen
spec:
route:
groupBy: ['alertname']
groupWait: 30s
groupInterval: 5m
repeatInterval: 12h
receiver: 'Critical'
continue: false
routes:
- receiver: 'Critical'
match:
severity: critical
receivers:
- name: Critical
emailConfigs:
- to: 'wangxiansen@boysec.cn'
html: '{{ template "email.html" . }}' # 添加 与模板中的 define 对应
sendResolved: true
更新报警配置
kubectl apply -f alertmanagerconfig.yaml
查看新生成的告警邮件
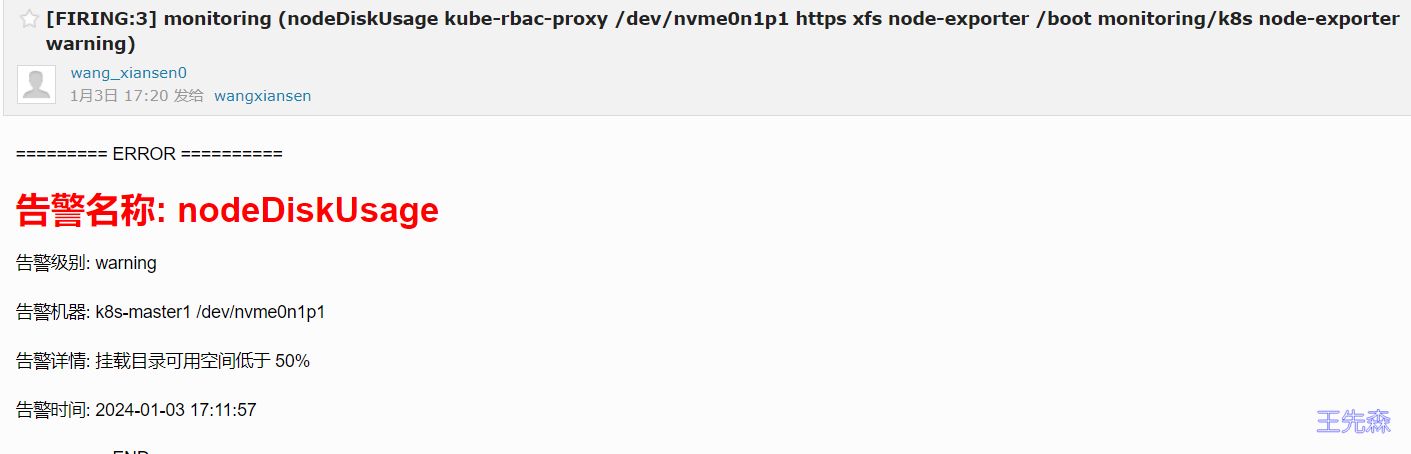
报警过滤
有的时候可能报警通知太过频繁,或者在收到报警通知后就去开始处理问题了,这个期间可能报警还在频繁发送,这个时候我们可以去对报警进行静默设置。
静默通知
在 Alertmanager 的后台页面中提供了静默操作的入口。
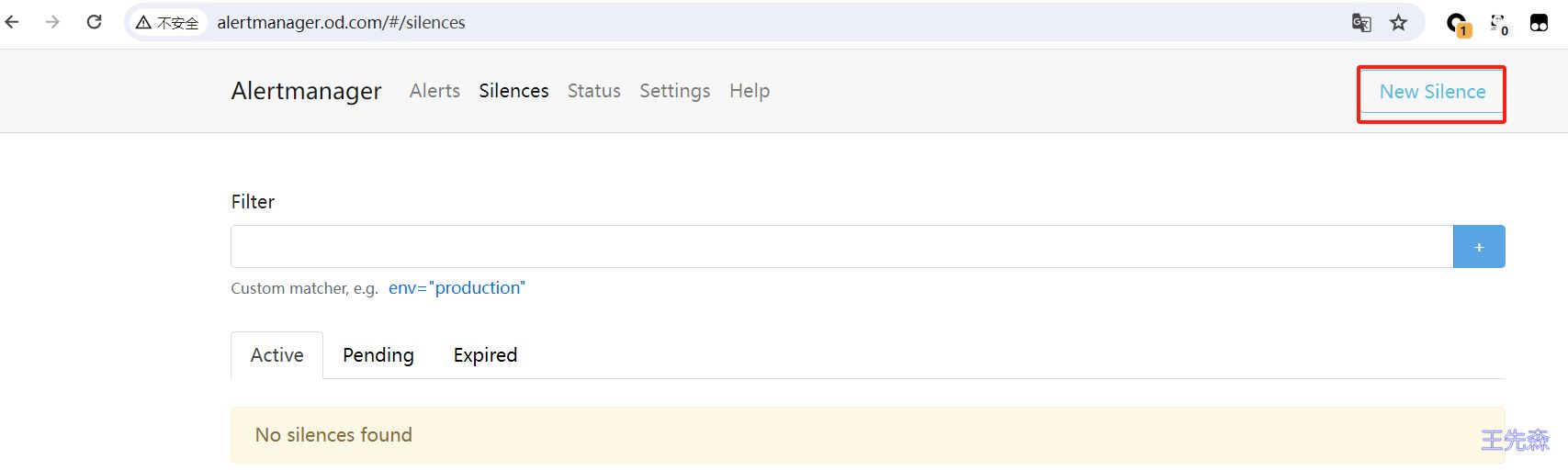
可以点击右上面的 New Silence 按钮新建一个静默通知
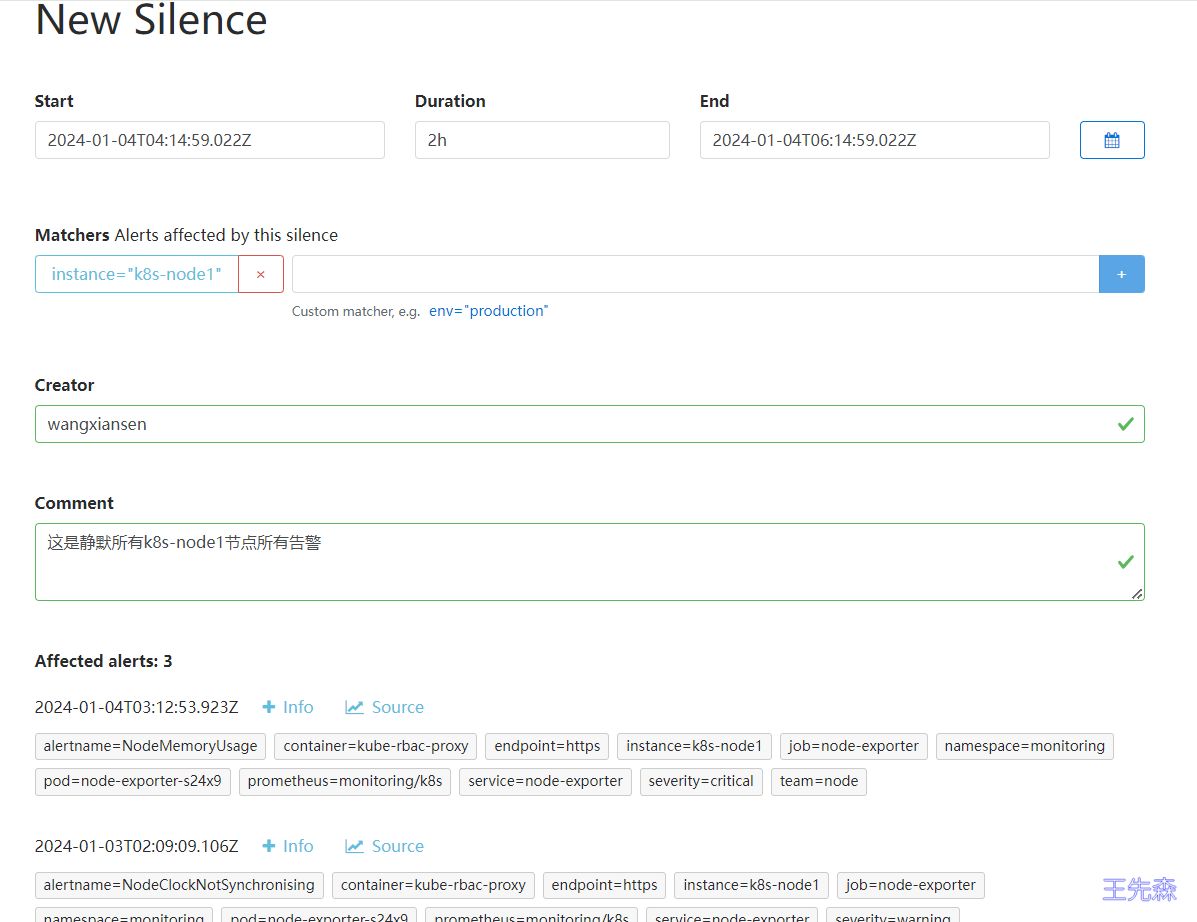
我们可以选择此次静默的开始时间、结束时间,最重要的是下面的 Matchers 部分,用来匹配哪些报警适用于当前的静默,比如这里我们设置 instance=k8s-node1 的标签,则表示具有这个标签的报警在 2 小时内都不会触发报警,点击下面的 Create 按钮即可创建:
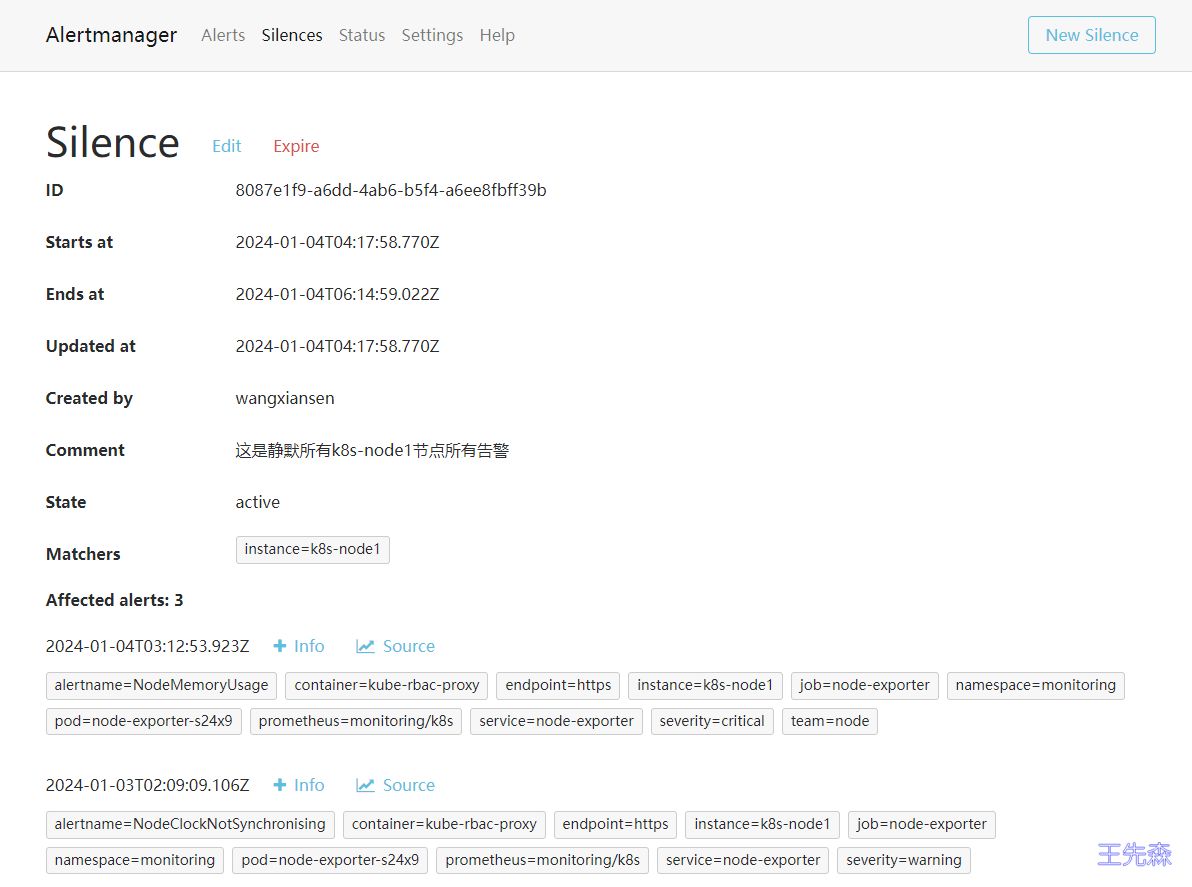
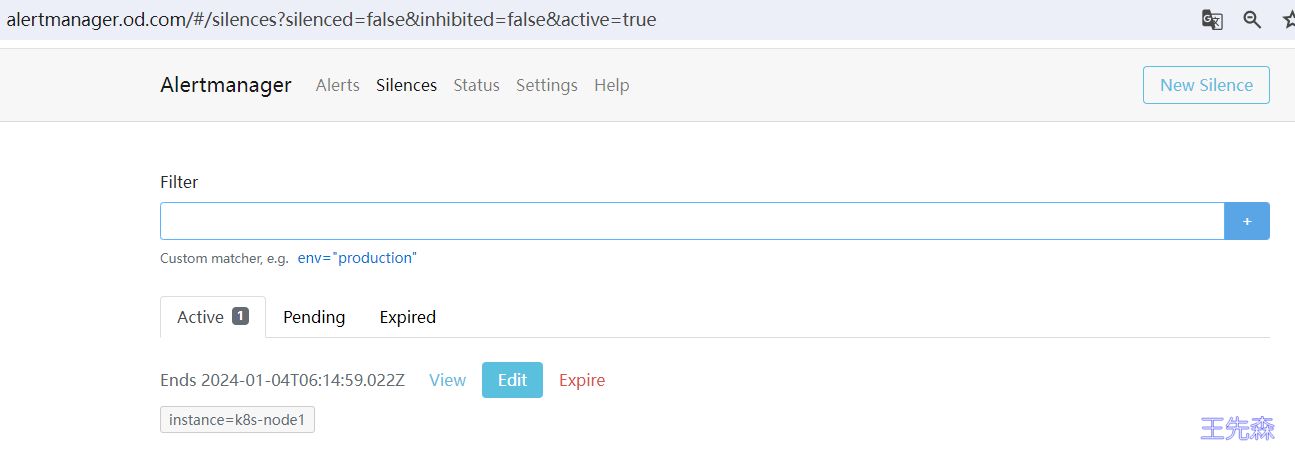
创建完成后还可以对该配置进行编辑或者让其过期等操作。此时在静默列表也可以看到创建的静默状态。
抑制报警规则
除了上面的静默机制之外,Alertmanager 还提供了抑制机制来控制告警通知的行为。抑制是指当某次告警发出后,可以停止重复发送由此告警引发的其他告警的机制,比如现在有一台服务器宕机了,上面跑了很多服务都设置了告警,那么肯定会收到大量无用的告警信息,这个时候抑制就非常有用了,可以有效的防止告警风暴。
要使用抑制规则,需要在 Alertmanager 配置文件中的 inhibit_rules 属性下面进行定义,每一条抑制规则的具体配置如下:
target_match:
[ <labelname>: <labelvalue>, ... ]
target_match_re:
[ <labelname>: <regex>, ... ]
target_matchers:
[ - <matcher> ... ]
source_match:
[ <labelname>: <labelvalue>, ... ]
source_match_re:
[ <labelname>: <regex>, ... ]
source_matchers:
[ - <matcher> ... ]
[ equal: '[' <labelname>, ... ']' ]
当已经发送的告警通知匹配到 target_match 和 target_match_re 规则,当有新的告警规则如果满足 source_match 或者 source_match_re 的匹配规则,并且已发送的告警与新产生的告警中 equal 定义的标签完全相同,则启动抑制机制,新的告警不会发送。
比如现在我们如下所示的两个报警规则 NodeMemoryUsage 与 NodeLoad:
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: node
namespace: default
spec:
groups:
- name: node-mem
rules:
- alert: NodeMemoryUsage
annotations:
description: '{{$labels.instance}}: 内存使用率高于 30% (当前值为: {{ printf "%.2f" $value }}%)'
summary: '{{$labels.instance}}: 检测到高内存使用率'
expr: |
(node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) /
node_memory_MemTotal_bytes * 100 > 30
for: 1m
labels:
team: node
severity: critical
- name: node-load
rules:
- alert: NodeLoad
annotations:
summary: '{{ $labels.instance }}: 低节点负载检测'
description: '{{ $labels.instance }}: 节点负载低于 1 (当前值为: {{ $value }})'
expr: node_load5 < 1
for: 2m
labels:
team: node
severity: normal
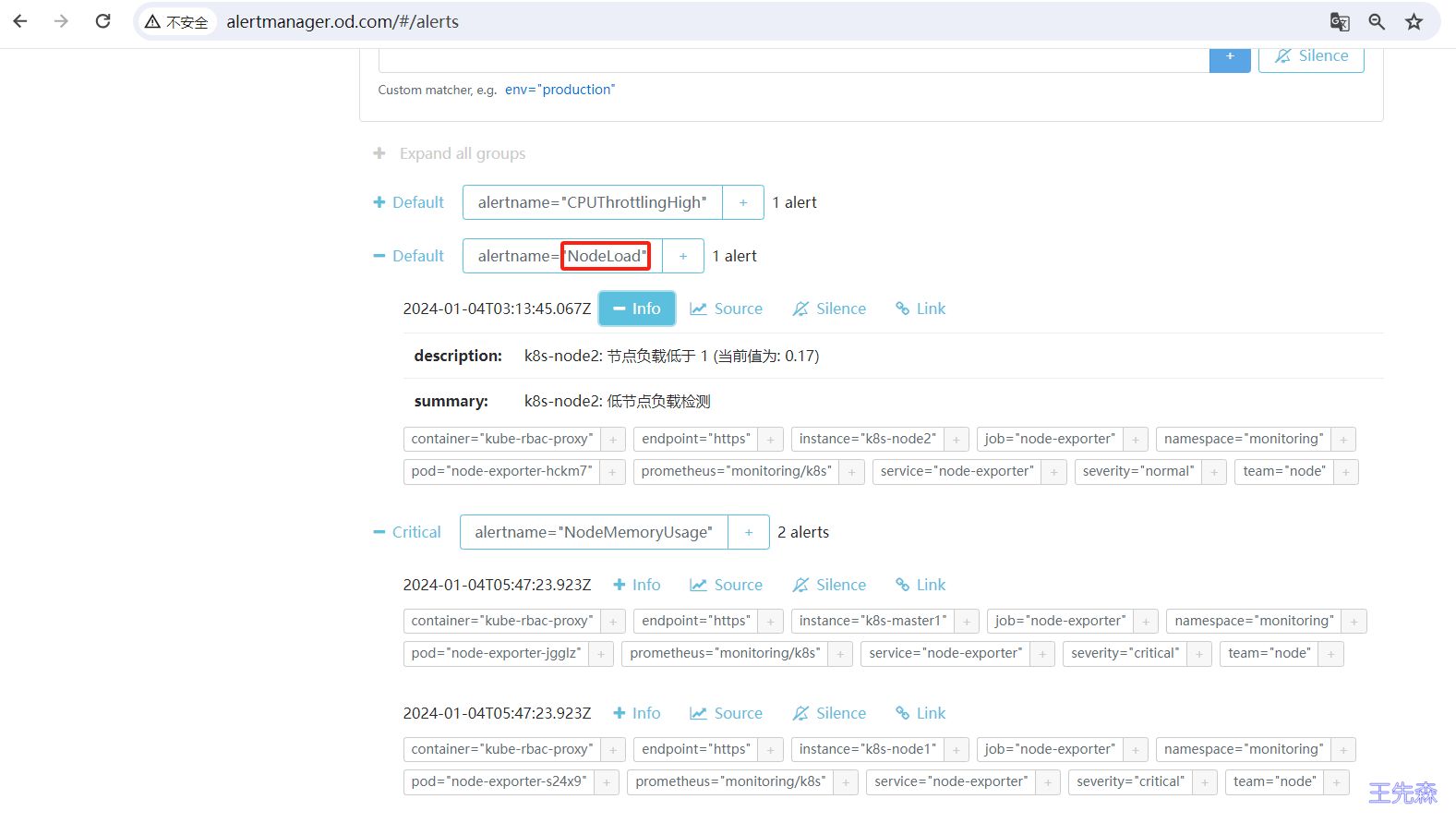
当前我们系统里面普通(severity: normal)的告警有三条,k8s-node1、k8s-node2 和 k8s-master 三个节点,另外一个报警也有俩条,k8s-node1和 k8s-master 三个节点:
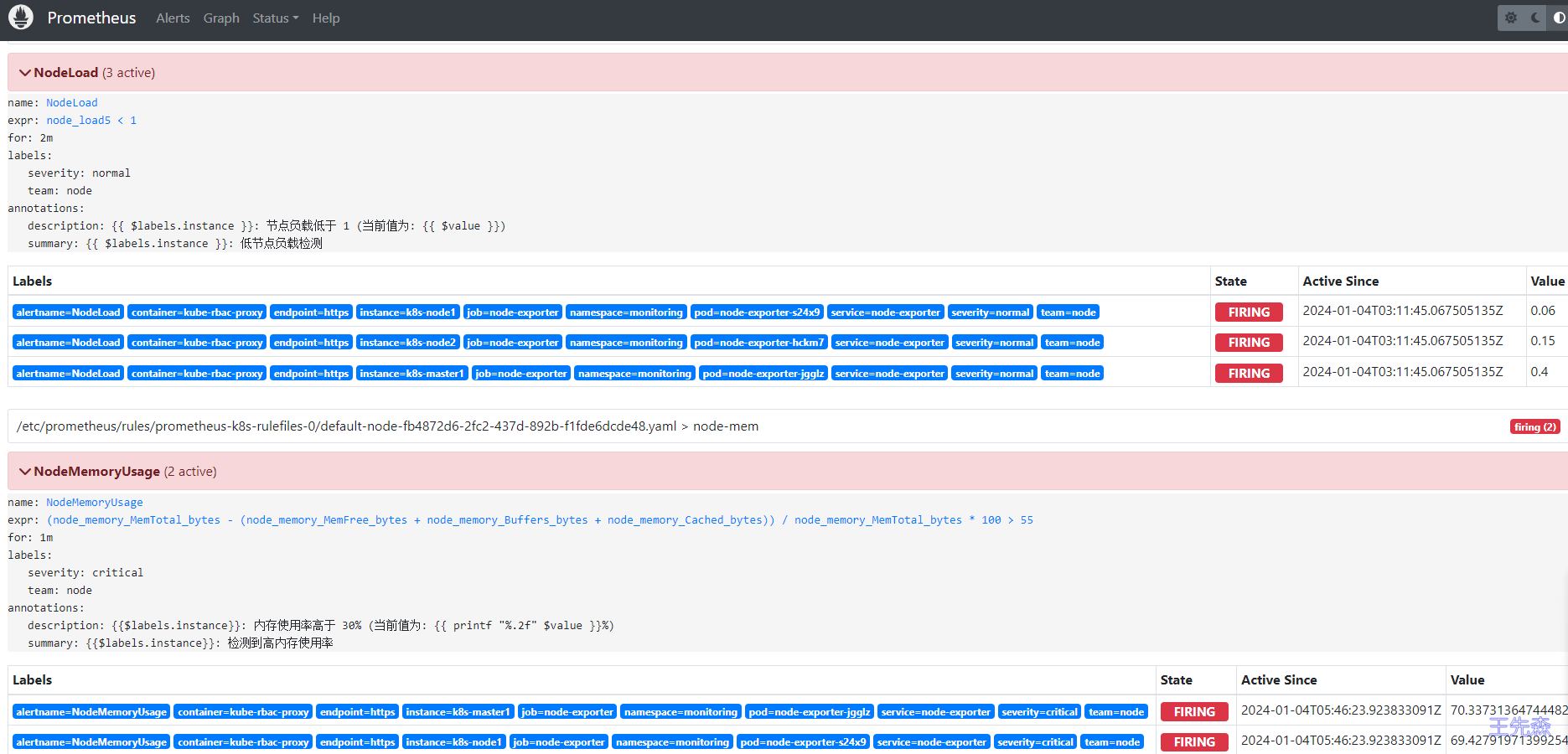
现在我们来配置一个抑制规则,如果 NodeMemoryUsage 报警触发,则抑制 NodeLoad 指标规则引起的报警,我们这里就会抑制 k8s-master 和 k8s-node1 节点的告警,只会剩下 k8s-node2 节点的普通告警。
通过修改Alertmanager 配置文件中添加如下所示的抑制规则:
apiVersion: monitoring.coreos.com/v1alpha1
kind: AlertmanagerConfig
metadata:
name: email-config
namespace: monitoring
labels:
alertmanagerConfig: wangxiansen
spec:
route:
groupBy: ['alertname']
groupWait: 30s
groupInterval: 5m
repeatInterval: 12h
receiver: 'Critical'
continue: false
routes:
- receiver: 'Critical'
match:
severity: critical
receivers:
- name: Critical
emailConfigs:
- to: 'wangxiansen@boysec.cn'
html: '{{ template "email.html" . }}'
sendResolved: true
inhibitRules:
- equal: ['instance']
sourceMatch:
- name: alertname
value: NodeMemoryUsage
- name: severity
value: critical
targetMatch:
- name: severity
value: normal
更新报警规则
kubectl create secret generic alertmanager-main -n monitoring --from-file=alertmanager.yaml --dry-run=client -o yaml > alertmanager-main-secret.yaml
kubectl apply -f alertmanager-main-secret.yaml
更新配置后,最好重建下 Alertmanager,这样可以再次触发下报警,可以看到只能收到 k8s-node2 节点的 NodeLoad 报警了,另外两个节点的报警被抑制了: