LVS 和 nginx 作为一个常用的负载均衡软件,充当集群流量入口的角色,需要承载的业务流量一般都比较大,这个时候对LVS/Nginx节点进行一些参数调优,对于发挥它们的性能有很大的帮助。
一、 可能会负载均衡器性能的因素
1. 硬件方面
CPU 、内存、 网卡 。
其中最主要的是 cpu 和网卡,短连接业务场景下cpu软中断si可能成为性能瓶颈;网卡的最大流量值也可能限制负载均衡器性能的发挥,如常见的 千兆网卡 ,理论最大数据传输速率为1000Mb/s,即125MB/S。LVS对于内存消耗并不多,Nginx相对会消耗内存一些,不过内存一般不会成为瓶颈。
2. 系统方面
Linux系统默认有许多限制,对于在业务流量较大的情况下发挥负载均衡器的性能有很大影响。常见的如: 服务端可接受的最大连接数、可接受的最大半连接数、本地可用端口范围、time-wait连接数、可打开的最大文件句柄数、网卡等待队列大小等。
3. 软件方面
LVS的 hash table 值,Nginx的nginx.conf调优等。
4. 网络方面
负载均衡器和真实服务器都是通过网络进行通信,如果条件允许,最好将它们置于同机房、同网段下,减小网络时延带来的影响。
二、性能调优介绍
1. 系统参数调优
1.1 网卡多队列与CPU核绑定
网卡多队列是一种硬件技术,即一个物理网卡可以有多个队列通道,需要多队列网卡驱动支持。默认情况下各个队列的请求都是由cpu0核处理,所以很容易因为cpu0核si满造成性能瓶颈。如下所示:
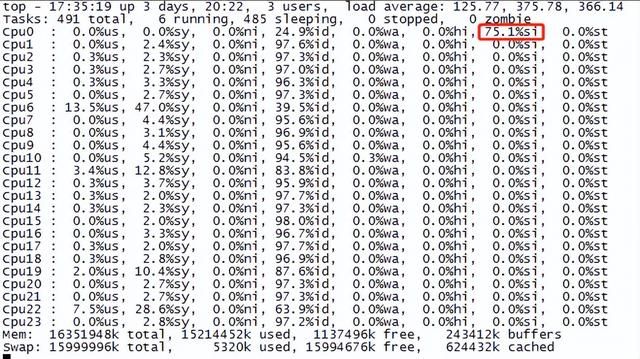 cpu软中断集中在单个核上
cpu软中断集中在单个核上
多队列网卡在系统中有多个中断号,通过CPU核绑定,将各个中断号对应的网卡队列绑定到指定的CPU核处理,这样可以发挥多核CPU的优势,将中断请求分摊到多个cpu核上,提升cpu处理性能。
配置方法:
a. 检查系统是否已开启irqbanlance服务,如果有,则关闭该服务,手动进行cpu核绑定。
# ps -ef | grep irqbalance
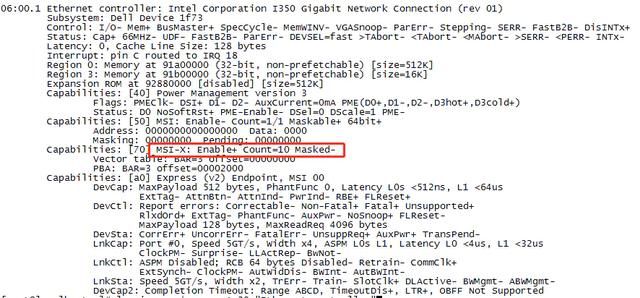
b. 检查网卡是否支持多队列
#lspci -vvv | grep -A 30 “Ethernet controller”
检查是否存在 MSI-X: Enable+ Count >0,如果存在,说明网卡支持多队列。
c. 查询网卡各队列对应的中断号
# cat /proc/interrupts | grep em3
如下图,可以看到em3网卡有8个队列,分别对应中断号187~194。

d. 将各队列绑定到指定的CPU核
# echo 1 > /proc/irq/187/smp_affinity
# echo 2 > /proc/irq/188/smp_affinity
# echo 4 > /proc/irq/189/smp_affinity
# echo 8 > /proc/irq/190/smp_affinity
# echo 10 > /proc/irq/191/smp_affinity
# echo 20 > /proc/irq/192/smp_affinity
# echo 40 > /proc/irq/193/smp_affinity
# echo 80 > /proc/irq/194/smp_affinity
PS: 这里传入的值为16进制。转换为2进制后对应绑定的cpu核。
如: echo 80 > cat /proc/irq/194/smp_affinity
16进制80转换为2进制为1000 0000,表示将中断号194绑定到cpu7核上面。
从下图可以看到做了网卡多队列与CPU核绑定后,中断处理分摊到了cpu0~7核,处理能力得到提升。
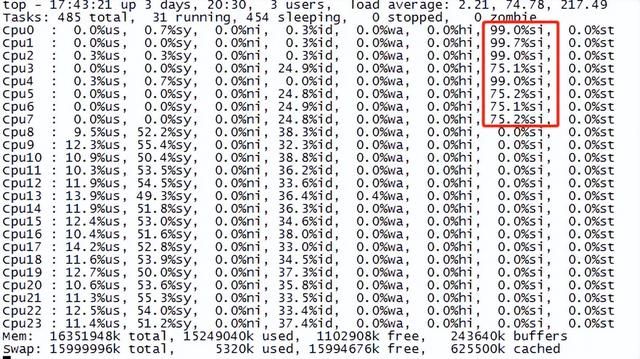 做了网卡多队列与CPU核绑定后的效果
做了网卡多队列与CPU核绑定后的效果
1.2 关注系统链接跟踪表大小
系统链接跟踪表记录了经过系统转发的连接信息,通过加载nf_conntrack模块启用, 对于 iptables 、SNAT/DNAT等功能是必须启用链接跟踪表的。
但是如果链接跟踪表的值设置的太小,容易造成链接跟踪表满导致丢包的问题。所以需要关注系统的链接跟踪表最大值和当前值的大小,当二者相等时,说明表满,系统会drop新的连接请求。
# sysctl -a | grep nf_conntrack_max (查询系统链接跟踪表最大值)
# sysctl -a | grep nf_conntrack_count (查询系统链接跟踪表当前值)
如下图中的链接跟踪表最大值为65536就太小了,很容易造成丢包。
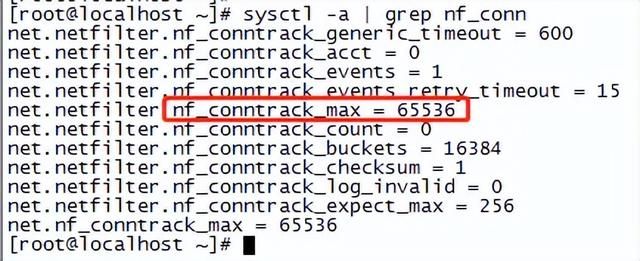
ps: 链接跟踪表设置大一些虽然不会造成丢包,但是在业务量很大的情况下,如果表过大(上百万的级别),系统查询链接跟踪表会消耗大量的cpu资源,可能会导致系统挂死。
1.3 关闭网卡LRO、GRO特性
现在大多数网卡都具有LRO/GRO功能,即 网卡收包时将同一流的小包合并成大包 (tcpdump抓包可以看到>MTU 1500bytes的数据包)交给 内核协议栈;LVS内核模块在处理>MTU的数据包时,会丢弃;
因此,如果我们用LVS来传输大文件,很容易出现丢包,传输速度慢;
解决方法,关闭LRO/GRO功能,命令:(注意查看命令是小k,修改命令是大K)
ethtool -k eth0 查看LRO/GRO当前是否打开
ethtool -K eth0 lro off 关闭GRO
ethtool -K eth0 gro off 关闭GRO
1.4 增大网卡的ring buffer值。
# ethtool -G em4 rx 4096
# ethtool -G em4 tx 4096
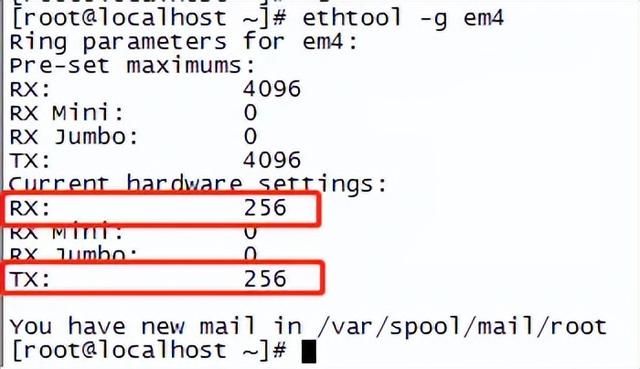
1.5 增大网卡等待队列大小
netdev_max_backlog参数表示每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。当网卡流量很大时,可以调大这个参数值。
# sysctl -w net.core.netdev_max_backlog=262144
1.6 增大服务端全连接队列大小
somaxconn参数表示服务端已完成3次握手连接的队列大小,即单个服务可建立的 tcp 连接最大值。当需要增大服务端处理并发连接的能力时,需要调大该参数值。
# sysctl -w net.core.somaxconn=262144
1.7 增大服务端半连接队列大小
tcp_max_syn_backlog参数表示服务端接收syn消息队列的大小。如果该队列未满,则响应(syn,ack)消息;否则将丢弃客户端的 syn 包。
# sysctl -w net.ipv4.tcp_max_syn_backlog=262144
1.8 增大系统可用的本地端口范围
# sysctl -w net.ipv4.ip_local_port_range=”1024 65535″
1.9 增大系统time_wait状态连接数限制
tcp_max_tw_buckets表示系统允许存在的time_wait状态连接数。Time wait状态是tcp断连中一个正常的状态,它存在的作用主要包括:确保tcp连接可靠的断开和旧连接的报文在网络中彻底消失。如果这个值过小,则客户端不会进入time_wait状态,而是直接从FIN_WAIT状态结束。这时候服务端最后一次挥手的FIN消息会以收到RST结束,可能会导致服务端断连异常。
# sysctl -w net.ipv4.tcp_max_tw_buckets=262144
1.10 启用time_wait状态连接复用
增大tcp_max_tw_buckets值有一个负面影响,就是系统time_wait状态连接过多,将可用端口耗尽,导致没有足够的可用端口新建连接。这时候可以启用time_wait状态连接复用。注意需要同时启用时间戳tcp_timestamps。(注意开启tcp_timestamps后要确认关闭tcp_tw_recycle)
# sysctl -w net.ipv4.tcp_timestamps=1
# sysctl -w net.ipv4.tcp_tw_reuse=1
1.11 增大系统最大文件句柄数
fs.file-max表示系统整体允许打开的最大文件句柄数。这个值一般只需关注一下,如果配置过小,可以增大。
# sysctl -a | grep fs.file-max
1.12 增大系统进程最大文件句柄数
ulimit -n查询的结果表示单个进程允许打开的最大文件句柄数,可用 ulimit -n xxx调大该参数值。
# ulimit -n
# ulimit -n xxx
注意这只是在当前 shell 下生效的,系统重启后会丢失,需要同时修改/etc/security/limits.conf中的nofile值。其中,* 这行的配置表示对非 root 用户生效。
* soft nofile 1024000
* hard nofile 1024000
root soft nofile 1024000
root hard nofile 1024000
2. LVS参数调优
2.1 增大ipvs模块hash table的大小
ipvs模块hash table默认值为2^12=4096,改为2^20=1048576。
可以用 ip vsadm -l命令查询当前hash table的大小。

修改方法:
在/etc/modprobe.d/目录下添加文件ip_vs.conf,内容为:
options ip_vs conn_tab_bits=20
重新加载ipvs模块。

3.Nginx参数调优
Nginx的参数配置都在nginx.conf文件中。
3.1 配置worker进程数等于系统cpu核数,并配置cpu核绑定。
worker_processes auto;
worker_cpu_affinity auto;
这里比较方便的是配置为auto,但是根据实际的系统情况指定worker进程数和手动绑定cpu核可能性能会更高一些,比如避开中断 irq 处理的cpu核,将worker进程绑定到其它空闲的cpu核上。
3.2 使用 epoll 模型
use epoll;
3.3 关闭TCP的Nagle算法
tcp_nodelay on;
Nagle算法 规定了一个TCP连接中最多只能存在一个未被确认的小包,这可能会和系统的延迟ACK机制产生冲突,造成较为严重的时延。
3.4 增大单个worker进程的文件句柄数限制
worker_rlimit_nofile 1024000;
3.5 增大单个worker进程的最大并发连接数限制
worker_connections 1024000;
这里的最大并发连接包括前后端的连接,且该参数值不能大于worker_rlimit_nofile。
4. 硬件与网络配置调优
4.1 对物理网卡做多网卡绑定
采用mode 0或mode 4对多块物理网卡做绑定,提升网卡整体的传输速率。如将两块传输速率为1000MB/S的网卡做mode0绑定,则理论上bond网卡的传输速率为2000MB/S。
4.2 将负载均衡器和真实服务器放在一个局域网内
负载均衡器和真实服务器靠网络传输数据,如果条件允许,将它们放在一个局域网内,避免数据传输走路由器传输。
三、性能分析工具
1. 分析cpu性能
top:按1可以看到每个cpu核的cpu使用情况,同时还能看到各个进程的情况。
sar -u 1:每隔1秒打印出当前cpu的整体使用情况。
mpstat -P ALL 1 :每隔1秒打印出所有cpu核的使用情况。
ps:sar和mastat需要安装sysstat工具包。
2. 分析网卡流量
sar -n DEV 1:每隔1秒打印出所有网卡的流量传输情况。
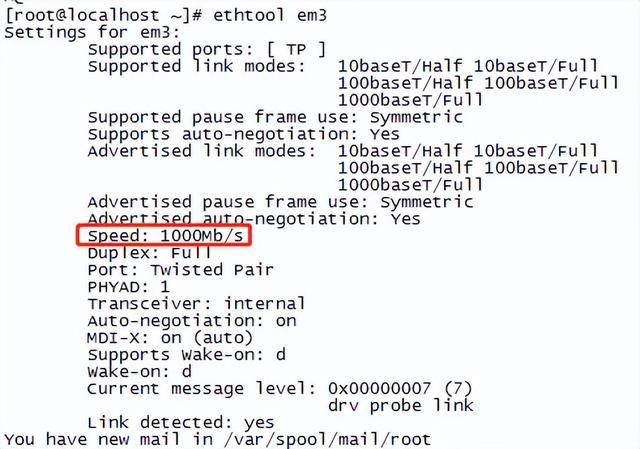
3. 查看网卡配置
# ethtool xxx
下图em3为千兆网卡,注意这里的单位是小b。
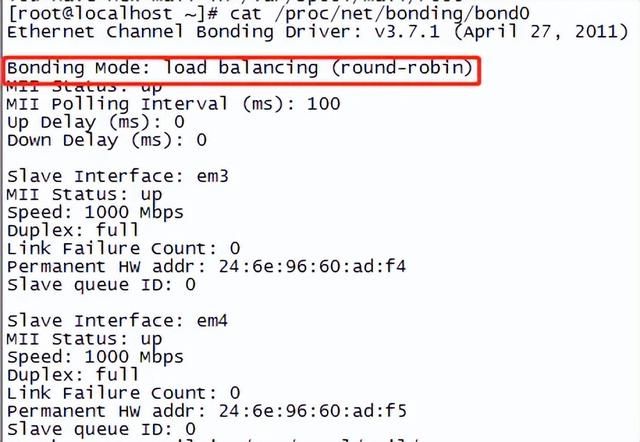
4. 查看bond网卡绑定模式
# cat /proc/net/bonding/xxx
下面的bond0网卡的绑定模式为mode0, 轮询 。
四、 性能压测工具
这里介绍一个很好用的http压测工具: wrk 。
1. 安装方法
#git clone
# make
# ln -s xxx/wrk /usr/sbin/wrk
2. 使用方法
使用方法: wrk <选项> <被测HTTP服务的URL>
Options:
-c, –connections 跟服务器建立并保持的TCP连接数量
-d, –duration 压测时间
-t, –threads 使用多少个线程进行压测
-s, — script 指定 Lua 脚本路径
-H, — header 为每一个HTTP请求添加HTTP头
–latency 在压测结束后,打印延迟统计信息
–timeout 超时时间
-v, –version 打印正在使用的wrk的详细版本信息
代表数字参数,支持国际单位 (1k, 1M, 1G)
代表时间参数,支持 时间单位 (2s, 2m, 2h)
3. 示例
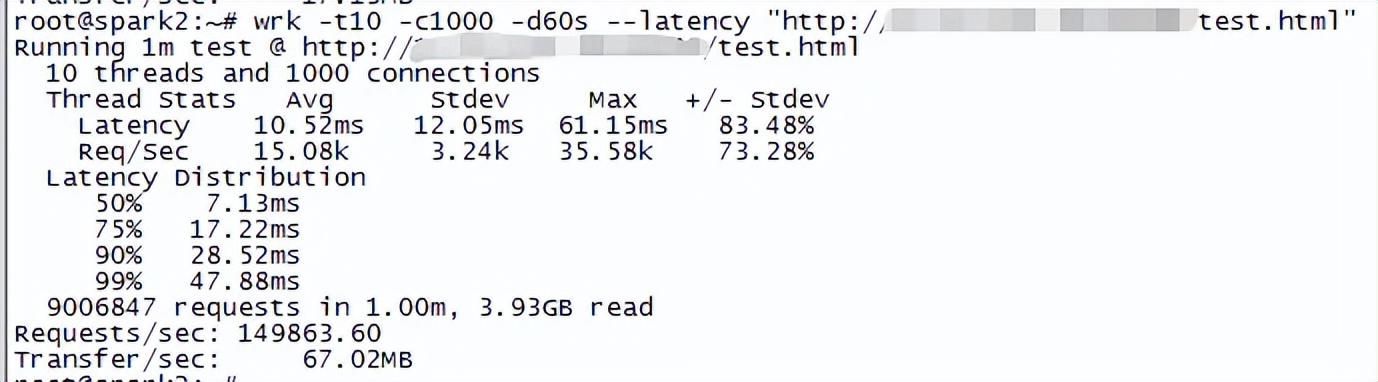
wrk默认为http长连接。
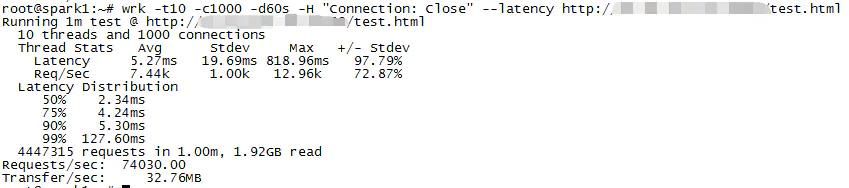
使用10个 线程 、1000个长连接对指定URL压测60s,并打印时延信息。
# wrk -t10 -c1000 -d60s –latency “#34;
Requests/sec: 149863.60 # 每秒的请求数,即QPS
Transfer/sec: 67.02MB # 每秒传输的字节数
指定头域实现http短连接测试。
# wrk -t10 -c1000 -d60s -H “Connection: Close” –latency “”