大家好,又见面了,我是你们的朋友全栈君。
怎样查看robots文件?
浏览器输入 主域名/robots.txt
robots.txt的作用
robots.txt 文件规定了搜索引擎抓取工具可以访问网站上的哪些网址,并不禁止搜索引擎将某个网页纳入索引。如果想禁止索引(收录),可以用noindex,或者给网页设置输入密码才能访问(因为如果其他网页通过使用说明性文字指向某个网页,Google 在不访问这个网页的情况下仍能将其网址编入索引/收录这个网页)。
robots.txt 文件主要用于管理流向网站的抓取工具流量,通常用于阻止 Google 访问某个文件(具体取决于文件类型)。
如果您使用 robots.txt 文件阻止 Google 抓取网页,有时候其网址仍可能会显示在搜索结果中(通过其他链接找到),但搜索结果不会包含对该网页的说明:
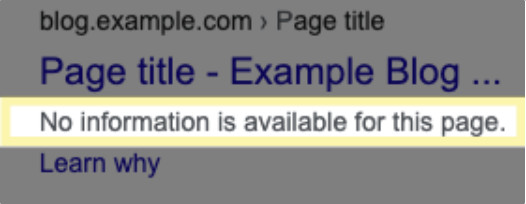
如果在加载网页时跳过诸如不重要的图片、脚本或样式文件之类的资源不会对网页造成太大影响,可以使用 robots.txt 文件屏蔽此类资源。不过,如果缺少此类资源会导致 Google 抓取工具更难解读网页,请勿屏蔽此类资源,否则 Google 将无法有效分析有赖于此类资源的网页。
例如:
robots.txt指令的一些限制
并非所有搜索引擎都支持 robots.txt 指令。
robots.txt 文件中的命令并不能强制规范抓取工具对网站采取的行为;是否遵循这些命令由抓取工具自行决定。Googlebot 和其他正规的网页抓取工具都会遵循 robots.txt 文件中的命令,但其他抓取工具未必如此。
不同的抓取工具会以不同的方式解析语法。
虽然正规的网页抓取工具会遵循 robots.txt 文件中的指令,但每种抓取工具可能会以不同的方式解析这些指令。
如果其他网站上有链接指向被 robots.txt 文件屏蔽的网页,则此网页仍可能会被编入索引
尽管 Google 不会抓取被 robots.txt 文件屏蔽的内容或将其编入索引,但如果网络上的其他位置有链接指向被禁止访问的网址,我们仍可能会找到该网址并将其编入索引。
如何创建robots文件?
用任意文本编辑器(就是写代码的软件)创建 robots.txt 文件。
格式和位置规则:
- 文件必须命名为 robots.txt。
- 网站只能有 1 个 robots.txt 文件。
- robots.txt 文件必须位于其要应用到的网站主机的根目录下。例如,若要控制对
https://www.example.com/下所有网址的抓取,就必须将 robots.txt 文件放在https://www.example.com/robots.txt下,一定不能将其放在子目录中(例如https://example.com/pages/robots.txt下)。 - robots.txt 文件可应用到子网域(例如
https://website.example.com/robots.txt)或非标准端口(例如http://example.com:8181/robots.txt)。 - robots.txt 文件必须是采用 UTF-8 编码(包括 ASCII)的文本文件。Google 可能会忽略不属于 UTF-8 范围的字符,从而可能会导致 robots.txt 规则无效。
robots文件的书写规则
- robots.txt 文件包含一个或多个组。
- 每个组由多条规则或指令(命令)组成,每条指令各占一行。每个组都以
User-agent行开头,该行指定了组适用的目标。 - 每个组包含以下信息:
- 组的适用对象(用户代理)
- 代理可以访问的目录或文件。
- 代理无法访问的目录或文件。
- 抓取工具会按从上到下的顺序处理组。一个用户代理只能匹配 1 个规则集(即与相应用户代理匹配的首个最具体组)。
- 系统的默认假设是:用户代理可以抓取所有未被
disallow规则屏蔽的网页或目录。 - 规则区分大小写。例如,
disallow: /file.asp适用于https://www.example.com/file.asp,但不适用于https://www.example.com/FILE.asp。 #字符表示注释的开始处。
对着着示例说明:
# Example 1: Block only Googlebot
User-agent: Googlebot
Disallow: /
# Example 2: Block Googlebot and Adsbot
User-agent: Googlebot
User-agent: AdsBot-Google
Disallow: /
# Example 3: Block all but AdsBot crawlers
User-agent: *
Disallow: /
Sitemap: http://www.example.com/sitemap.xml
user-agent:[必需,每个组需含一个或多个 User-agent 条目] 该指令指定了规则适用的自动客户端(即搜索引擎抓取工具)的名称。这是每个规则组的首行内容。示例里是谷歌蜘蛛的名称,每个搜索引擎的蜘蛛名称不同。disallow:[每条规则需含至少一个或多个disallow或allow条目] 您不希望用户代理抓取的目录或网页(相对于根网域而言)。如果规则引用了某个网页,则必须提供浏览器中显示的完整网页名称。它必须以/字符开头;如果它引用了某个目录,则必须以/标记结尾。allow:[每条规则需含至少一个或多个disallow或allow条目] 上文中提到的用户代理可以抓取的目录或网页(相对于根网域而言)。此指令用于替换disallow指令,从而允许抓取已禁止访问的目录中的子目录或网页。对于单个网页,请指定浏览器中显示的完整网页名称。对于目录,请用/标记结束规则。sitemap:[可选,每个文件可含零个或多个 sitemap 条目] 相应网站的站点地图的位置。站点地图网址必须是完全限定的网址;Google 不会假定存在或检查是否存在 http、https、www、非 www 网址变体。
上传robots文件
加到网站的根目录(取决于网站和服务器架构)。
测试 robots.txt 标记
要测试新上传的 robots.txt 文件是否可公开访问,请在浏览器中打开无痕浏览窗口(或等效窗口),然后转到 robots.txt 文件的位置。例如:https://example.com/robots.txt。如果您看到 robots.txt 文件的内容,就可准备测试标记了。
测试工具:https://www.google.com/webmasters/tools/robots-testing-tool
常用的robots规则
# 禁止所有搜索引擎抓取整个网站
User-agent: *
Disallow: /
# 禁止所有搜索引擎抓取某一目录及其内容(禁止抓取的目录字符串可以出现在路径中的任何位置,因此 Disallow: /junk/ 与 https://example.com/junk/ 和 https://example.com/for-sale/other/junk/ 均匹配。)
User-agent: *
Disallow: /calendar/
Disallow: /junk/
Disallow: /books/fiction/contemporary/
# 只有 googlebot-news 可以抓取整个网站。
User-agent: Googlebot-news
Allow: /
User-agent: *
Disallow: /
# Unnecessarybot 不能抓取相应网站,所有其他漫游器都可以。
User-agent: Unnecessarybot
Disallow: /
User-agent: *
Allow: /
# 禁止所有搜索引擎抓取 useless_file.html 网页。
User-agent: *
Disallow: /useless_file.html
# 禁止访问 dogs.jpg 图片。
User-agent: Googlebot-Image
Disallow: /images/dogs.jpg
# 禁止 Google 图片访问您网站上的所有图片(如果无法抓取图片和视频,则 Google 无法将其编入索引。)
User-agent: Googlebot-Image
Disallow: /
# 禁止谷歌抓取所有 .gif 文件。
User-agent: Googlebot
Disallow: /*.gif$
# 禁止抓取整个网站,但允许 Mediapartners-Google 访问内容
User-agent: *
Disallow: /
User-agent: Mediapartners-Google
Allow: /
# 禁止谷歌抓取所有 .xls 文件。
User-agent: Googlebot
Disallow: /*.xls$
如何更新robots文件?
只需要通过https://example.com/robots.txt ,打开后复制到编辑器里,做出更改,再重新上传到根目录,再用GSC测试之后提交即可。(没有删除原先的robots文件这个步骤)
发布者:全栈程序员栈长
出处:https://javaforall.cn/133123.html