1.了解
1.1. 存放数据的地方 4
1.2. 前台–》后台—-》数据库 可以叫数据库,或数据库管理系统 4
1.3. 三范式 4
1.3.1. 1NF:最小原子 2NF:主键依赖 3NF:消除传递依赖 4
1.4. 创始人:拉里,埃里森 4
1.5. 基本单位是:用户,Oracle,是那个用户是有多少表,MySQL,这个数据库是有多少表 4
1.6. Oracle体系 4
2. 增删改 5
2.1. 当增删改的数据时,会自动开启事物,允许回滚一次,可以后退一次 5
2.2. 格式; insert into(所需插入的表名)values(所需插入的值) 5
3. 查询 select 5
3.1. 基础 5
3.1.1. where过滤行记录:就是过滤某些数据 6
3.1.2. 查询思路: 1、查询的数据 2、数据的来源 3、条件 6
3.1.3. 判断符号: 6
3.1.4. 条件逻辑符 6
3.1.5. 条件判断 7
3.1.6. 集合 7
3.1.7. 排序和分组 7
3.1.8. 函数 内置函数 8
3.1.9. 条件查询 9
3.1.10. 伪列 系统中存在,但是不会显示出来的,需要人工需要在手动列出来的 10
3.2. 联表查询 10
3.2.1. 92语法 10
3.2.2. 99语法 join左右放表名 on后面放条件 join和on一组一个,无法分开 11
4. 视图 12
4.1. 介于表(存在)与结果集(不存在)之间的虚拟表,可以存储的 12
4.2. 作用: 1、区分相同数据不同的查询 2、隐藏内部细节 3、重启:封装select语句,命名 12
4.3. 操作 13
4.3.1. 1、前提:creat view ->组 connet resource 2、授权:sqlplus/noking 3、sys登录:conn sys/123456@orcl as sysdba 4、授权:grant dba to scott; 5、回收:revoke dba from scott; 6、重新登录:create or replace view 视图名 as select 语句 [with read only] 7、删除视图:但不会删除结果集:drop view 视图名 13
5. 索引 13
5.1. 了解 13
5.1.1. 1、提高查询效率,对大量数据有效果,少量没有效果,因为需要数据库维护 2、索引的创建或删除,对外使用没有影响 3、类似于目录 13
5.2. 操作 13
5.2.1. 创建:create index 索引名 on 表名(字段列表) 13
5.2.2. 删除:drop index 索引名 13
5.2.3. 使用索引: select * from 表名 where 可跟字段列表判断语句 13
5.3. 创建索引注意事项: 1、唯一性较好的字段建立索引 2、大数据才有效果(万级别) 3、主键|唯一,唯一索引 13
6. 表设计与创建 14
6.1. 插入表 14
6.1.1. insert into 表名 values (按照创建表的规范插入信息) 14
6.2. 删除表 14
6.2.1. drop table 表名 14
6.3. 创建表 14
6.3.1. 规则: 1、满足三范式 2、表,字段,约束,表的关联 14
6.3.2. 创建表 14
6.3.3. 字段关键规范 14
6.4. 表设计 14
6.4.1. 拷贝已有的表结构 14
6.4.2. 创建表+约束,默认名字(没有名字) 15
6.4.3. 名词解释 1、主键:唯一且非空(primary key) 2、唯一: 唯一(unique) 3、非空:不能为空(not null) 4、默认: 自己不设定值,系统默认给值(default(sysdate)) 5、外键:参考其他表某个字段 6、检查:自定义规则(check(所检查的字段名的判断语句)) 15
6.4.4. 创建表+约束,指出名字 15
6.4.5. 创建表后在追加约束 16
6.4.6. 外键 16
6.4.7. 删除数据 17
6.4.8. 删表 17
6.5. delete(删除)和数据截断(truncate) 18
6.5.1. delete: 1、delete from表 :表中数据全删 2、delete from 表 where 条件 :满足条件可以删 3、默认开启事物 trancate: 1、不会开启事物 2、在表中结构检查,一旦被从表引用,不允许使用数据截断 18
7. 序列 18
7.1. 类似于快进,工具类 生成有规律的序号数字,为表中主键,或类似于主键字段设置值用的 18
7.2. 格式: creat sequence 序列名 start with 起始值 inrement by 步进 select 序列名 nextval(下一个)或currval(当前) 18
7.3. 关键字: 1、nextval(下一个) 2、currval(当前),第一次时使用当前,需要先使用一次nextval 18
8. 事物 18
8.1. 是为了保证数据的安全有效 19
8.2. 四个特点(ACID) 19
8.2.1. Atomic 原子性:事物中所有数据的修改,要么全部执行,要么全部不执行 Consistrnce 一致性:事物完成时,要使所有的数据都保证有一致性的状态 Isolation 独立性:事物应该在另一个事物对数据的修改前或修改以后进行访问 Durability 持久性:保证事物对数据库的修改持久有效,即使发生系统故障也不应该丢失 19
8.3. 脏读和幻读 19
8.3.1. 脏读: 读未提交 19
8.3.2. 不可重复读; 1、读未提交 2、读已提交 19
8.3.3. 幻读: 1、读未提交 2、读已提交 3、可重复读 19
8.4. 事物的开启 20
8.4.1. 做增删改操作的时候就会自动开启事物,增:insert 删:delete 改:unpdate:DML,管理语言 20
8.4.2. DCL :grant,revoke,控制语句,授权的,回收权限的,控制语言 20
8.4.3. 创建(create),修改(alter),删除(drop):DDL定义语言 20
8.5. 事物的关闭 20
8.5.1. 提交 1、正常执行ddl 2、comit命令 3、正常关闭客户端 4、dcl 关闭: 1、rollback 2、非法关闭 20
删除约束: 先修改表,在删除约束 alter table 表名 constraints 约束名 20
1.了解
1.1.存放数据的地方
1.2.前台–》后台—-》数据库
可以叫数据库,或数据库管理系统
1.3.三范式
1.3.1.1NF:最小原子
2NF:主键依赖
3NF:消除传递依赖
1.4.创始人:拉里,埃里森
1.5.基本单位是:用户,Oracle,是那个用户是有多少表,MySQL,这个数据库是有多少表
1.6.Oracle体系
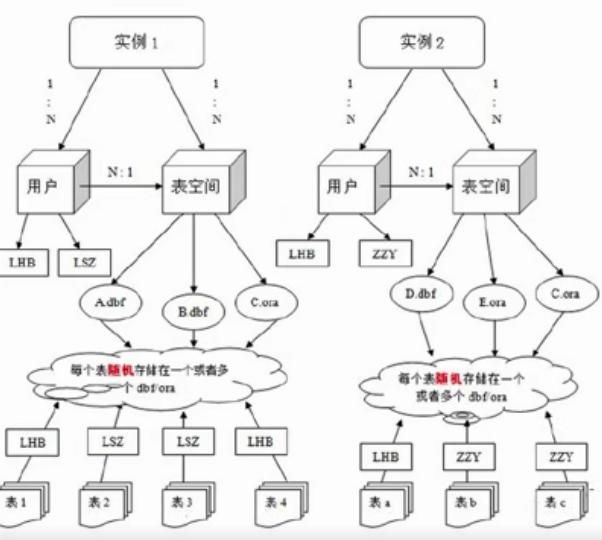
2.增删改
2.1.当增删改的数据时,会自动开启事物,允许回滚一次,可以后退一次
2.2.格式;
insert into(所需插入的表名)values(所需插入的值)
3.查询
select
3.1.基础
3.1.1.where过滤行记录:就是过滤某些数据
select 数据(结果集)from 表名 where 行过滤条件
注意:
1、在where中不能使用别名,因为执行流程问题,是先执行where在执行select
执行顺序
先找到表,在where判断是否有数据,后select查询结果集
from—>where——>select
3.1.2.查询思路:
1、查询的数据
2、数据的来源
3、条件
3.1.3.判断符号:
1、>:大于
2、<:小于
3、!=、<>:取反
4、>=:大于等于
5、<=:小于等于
6、=:等于
3.1.4.条件逻辑符
1、值1 or 值2:满足一个条件便可
2、值1 and 值2:需要两个条件都要
3、not 值:正体取反
4、between 值1 and 值2:值1<值2,包含值1和包含值2
5、空:null
6、in:相当于多个or,in(值1,值2,值3.。。。)满足里面多个条件,也可以子查询
7、exists 了解 存在即保留,存在即合法 select * from 数据来源 where 后 exists(结果集);
3.1.5.条件判断
1、is:是,条件判断
2、union all:去除重复行
3、is null:不存在,空
4、别名:as 或 空格
5、“”,双引号:原样输出
6、‘’,单引号:字符串,比较值
7、nvl(值1,值2):当值1为空null,取值2,当值1不为空null,取值1
8、||:字符串拼接
9、null和数字运算还是null
10、distinct:去重
3.1.6.集合
1、全集:Union all,俩张表合并在一起,不去重
2、并集:Union,俩张表合并在一起,去重
3、差集:Minus,大结果集减小结果集,重复的没有了,多余的出来了
4、交集:Intersent,两个表重复的,找出来
3.1.7.排序和分组
排序
order by
desc:降序
不写默认升序
执行流程:from—>where—–>select—–>order by
nulls first:默认是把null排后面,加first可以把null排前面
分组
group by
3.1.8.函数
内置函数
单行函数
单行记录都能返回一个结果
日期函数:
1、sysdate:当前日期
2、select 当前日期可加减 from 表名
3、add_months():可以按月份加,add_months(当前时间表名,几个月)
4、last_day():当月最后一天,括号内放当前时间表名
5、next_day(sysdate,’星期一’) 下一个要过的
6、to_date(c,m) 字符串以指定格式转换为日期
7、to_char(d,m) 日期以指定格式转换为字符串 :如果出现中文,前后添加””
8、判定函数 decode(字段,值1,结果1,值2 , 结果2,…, 默认值)
多行函数
多行记录返回一个结果
聚合函数:
1、count():一行算一个
2、sum:总和
3、max():最高
4、min():最低
5、avg():平均
注意;
1、当select后使用了聚合函数,就不能用非聚合函数,非分组函数
2、null不参与聚合函数运算(包含avg平均聚合函数)
3、where后面不能跟聚合函数,having后可以跟聚合函数
分组函数:
group by
格式;
select 数据 from 数据来源 where 行过滤条件 group by 分组字段 order by 排序字段
执行流程;
from—>where—->group by—–>select (聚合函数)—->order by
行转列
select 分组函数 聚合函数(单行函数 decode(字段,值1,值2),单行函数 decode(字段,值1,值2),单行函数 decode(字段,值1,值2)) from 表名 group by 分组函数名
3.1.9.条件查询
模糊查询:like ‘%a%,精准匹配:like‘具体的名字’效率低
like经常和%,_配合使用
1、%任意个任意字符
2、_占用一个字符
3、escape(‘单个字符’)指转义符,例子;like ‘%a%%’ escape(‘a’)
3.1.10.伪列
系统中存在,但是不会显示出来的,需要人工需要在手动列出来的
rovid
相当于每一条数据的记录地址,在数据插入数据库的时候就已经存在,需要人工自行添加rovid伪列才会得到地址
作用;区分重复数据
1、在有主键,唯一,非空,可根据主键区分
2、若没有主键,重复数据,区分数据可以用rovid
rownum
rownum是结果集才有的序号,一个select 一个rownum序号,伪列从1开始,每次加1
若where后rownum不确定,需要确定结果集,在判断,就不会有问题
分页查询
例子:
select ename, sal, rownum, num//查询确定的结果集
from (select ename, sal, rownum num from emp )//确定结果集
where num > 5//操作rownum序号
and num < 10
order by sal;
3.2.联表查询
3.2.1.92语法
内连接
连接条件,就是在where后面
等值连接
若是在表中有多个相同的字段,需指明出处,加别名
非等值连接
俩张表没有同名字段,也可实现非等值连接,范围连接便可
自连接
一张表,给俩个别名,相当一复制一份,进行自己和自己连接
笛卡尔积
俩张表连接,会有许多不需要的数据也会显示出来,造成很多冗余,给系统浪费很多空间,已经增加处理时间
外连接
外左连接
在from表名出,逗号左边为左连接
外右连接
在from表名出,逗号右边为右连接
在where后连接条件后加(+)相当于非主表
3.2.2.99语法
join左右放表名
on后面放条件
join和on一组一个,无法分开
笛卡尔积
cross join
内连接
自然连接
natural join
连接条件
join …..on(可做等值,也可以做非等值)
同名字段:join using 指定那一个字段做等值连接,不能指明出处
外连接
左连接
left join on:写在左边,主表在左
全连接
full join:俩个表都可以成为主表,等值的才连接
右连接
right join on :主表在右,主表在右
4.视图
4.1.介于表(存在)与结果集(不存在)之间的虚拟表,可以存储的
4.2.作用:
1、区分相同数据不同的查询
2、隐藏内部细节
3、重启:封装select语句,命名
4.3.操作
4.3.1.1、前提:creat view ->组 connet resource
2、授权:sqlplus/noking
3、sys登录:conn sys/123456@orcl as sysdba
4、授权:grant dba to scott;
5、回收:revoke dba from scott;
6、重新登录:create or replace view 视图名 as select 语句 [with read only]
7、删除视图:但不会删除结果集:drop view 视图名
5.索引
5.1.了解
5.1.1.1、提高查询效率,对大量数据有效果,少量没有效果,因为需要数据库维护
2、索引的创建或删除,对外使用没有影响
3、类似于目录
5.2.操作
5.2.1.创建:create index 索引名 on 表名(字段列表)
5.2.2.删除:drop index 索引名
5.2.3.使用索引:
select * from 表名 where 可跟字段列表判断语句
5.3.创建索引注意事项:
1、唯一性较好的字段建立索引
2、大数据才有效果(万级别)
3、主键|唯一,唯一索引
6.表设计与创建
6.1.插入表
6.1.1.insert into 表名 values (按照创建表的规范插入信息)
6.2.删除表
6.2.1.drop table 表名
6.3.创建表
6.3.1.规则:
1、满足三范式
2、表,字段,约束,表的关联
6.3.2.创建表
create table 表名 (字段名,类名,约束,字段。。。。。)
6.3.3.字段关键规范
1、字段名 bumber(5,2):5代表是整数精确5位,2是小数点后2位,可以不要2,只要整数,也可以要小数点
2、字段名 varchar2(6):默认是6个字节一个汉字是3个字节,varchar2(6 char):默认是6个汉字
3、字段名 date :时间规范
6.4.表设计
6.4.1.拷贝已有的表结构
1、creat table 需要创建表名 as select 字段列表 from 已有表名 where 1!=1:只有表头
2、creat table 需要创建表名 as select 字段列表 from 已有表名 :会拷贝出表头和里面的内容
6.4.2.创建表+约束,默认名字(没有名字)
格式:
直接在创建表的时候在语句后面加约束(约束没有名字)
优缺点;
1、书写简单
2、不便于后期维护
6.4.3.名词解释
1、主键:唯一且非空(primary key)
2、唯一: 唯一(unique)
3、非空:不能为空(not null)
4、默认: 自己不设定值,系统默认给值(default(sysdate))
5、外键:参考其他表某个字段
6、检查:自定义规则(check(所检查的字段名的判断语句))
6.4.4.创建表+约束,指出名字
参见: 删除约束:
先修改表,在删除约束
alter table 表名 constraints 约束名 (因为有约束名)
1、在创建表的时候在语句的后面添加约束之前给约束加个别名(constraints 别名)
关键字:
constraints
2、在创建表的时候在已经结束语句的时候,把从constraints开始到结尾的,放到下一行
优点:
因为约束有了名字,类似于有了java报出异常,见名知意,可以迅速找到问题点,解决问题
6.4.5.创建表后在追加约束
参见: 删除约束:
先修改表,在删除约束
alter table 表名 constraints 约束名 (因为有约束名)
先修改表,在追加约束
alter table 表名 add constraints 到结尾
关键字;
1、alter 修改
2、add 追加
6.4.6.外键
创建外键
关键字:
references
格式:
表名 关键子 references 子表名(字段名)
在父表中创建一个和子表中一样的字段名与关键字,用外键关键字,子表表名(字段名)
外键约束,有外键约束的是从表
关键子:
foreign key
追加外键约束:
先修改表名追加约束给个约束别名外键约束父表字段名约束字表表名(字段名)
格式;
alter 关键字 父表名 add constraints 约束别名 foreign key (父表的字段名)reference 字表表名(字段名)
6.4.7.删除数据
1、设置表中主外键后加on delete set null
在删除某一个数据delete from 父表名 where sid=01(判断语句);只会没有主外键的一个空了
2、先删从表在删主表
alter table 子表名 drop column 主外键字段名;
alter table 父表名 drop column 主外键字段名;
3、设置表主外键后on delete cascade
在删除某一个数据delete from 父表名 where sid=01(判断语句);会整行没有
6.4.8.删表
1、先子后父,分开操作删表,默认和一起操作无序分开操作
drop table 子表名;
drop table 父表名;
2、主表后cascode costranit
drop table 父表名 cascode costranit;
6.5.delete(删除)和数据截断(truncate)
6.5.1.delete:
1、delete from表 :表中数据全删
2、delete from 表 where 条件 :满足条件可以删
3、默认开启事物
trancate:
1、不会开启事物
2、在表中结构检查,一旦被从表引用,不允许使用数据截断
7.序列
7.1.类似于快进,工具类
生成有规律的序号数字,为表中主键,或类似于主键字段设置值用的
7.2.格式:
creat sequence 序列名 start with 起始值 inrement by 步进
select 序列名 nextval(下一个)或currval(当前)
7.3.关键字:
1、nextval(下一个)
2、currval(当前),第一次时使用当前,需要先使用一次nextval
8.事物
8.1.是为了保证数据的安全有效
8.2.四个特点(ACID)
8.2.1.Atomic 原子性:事物中所有数据的修改,要么全部执行,要么全部不执行
Consistrnce 一致性:事物完成时,要使所有的数据都保证有一致性的状态
Isolation 独立性:事物应该在另一个事物对数据的修改前或修改以后进行访问
Durability 持久性:保证事物对数据库的修改持久有效,即使发生系统故障也不应该丢失
8.3.脏读和幻读
8.3.1.脏读:
读未提交
意思;
事物T1更新了一行数据,还没有提交所做的修改,T2读取更新后的数据,T1回滚,T2读取数据无效
8.3.2.不可重复读;
1、读未提交
2、读已提交
8.3.3.幻读:
1、读未提交
2、读已提交
3、可重复读
意思;
事物T1读取一条带WHERE条件的语句,返回结果集,T2插入一条新纪录,恰好也是T1where的条件,T1再次查询,结果集中又看到T2的记录,新纪录就叫幻读
8.4.事物的开启
8.4.1.做增删改操作的时候就会自动开启事物,增:insert 删:delete 改:unpdate:DML,管理语言
8.4.2.DCL :grant,revoke,控制语句,授权的,回收权限的,控制语言
8.4.3.创建(create),修改(alter),删除(drop):DDL定义语言
8.5.事物的关闭
8.5.1.提交
1、正常执行ddl
2、comit命令
3、正常关闭客户端
4、dcl
关闭:
1、rollback
2、非法关闭
删除约束:
先修改表,在删除约束
alter table 表名 constraints 约束名
参见: 创建表+约束,指出名字 (因为有约束名), 创建表后在追加约束 (因为有约束名)