文章介绍:笔者对Go语言知识进行体系化总结,有一定全面性与深度。
简介
历史与发展
- Go 语言由Google开发,起源于 2007 年,开源于 2009 年。
- 诞生背景,主要是解决其他语言的历史包袱重、复杂、编译慢等问题。
- 其设计理念是less is more,追求简洁、高效、直接。
- 由 Go 开发的开源项目:go、docker、k8s、etcd等。
语言特性
- 编译型,区别于脚本等解释性语言。
- 静态强类型,类型是编译期确定的,需先声明后使用。
- 内存安全,支持内存安全检查和垃圾回收。
- 并发支持,协程作为并发单元,运行层深度优化。
- 不支持继承、泛型等复杂特性。
安装
安装与环境配置
从 go.dev 上下载 Go 安装包,解压至 /usr/local 目录下。增加/usr/local/go/bin路径到PATH环境变量。
Go 的环境变量:
名称 | 描述 |
GOROOT | 安装目录,包含编译器、命令行工具、标准库等。 |
GOPATH | 工作目录,包含自动下载的第三方依赖源码和可执行文件。 |
GO111MODULE | 模块管理模式,默认值是 auto 表示根据当前目录来判断。 |
GOPROXY | 模块代理地址,用于下载公开的第三方依赖,多个用逗号隔开,遇到 direct 时表示直接访问源地址。 |
GOSUMDB | 使用 GOPROXY 时,校验和数据库的地址。 |
GONOPROXY | 不通过代理,直接下载的第三方依赖,如公司私有仓库。 |
GONOSUMDB | 不通过代理,直接下载的第三方依赖校验和数据库。 |
GOPRIVATE | 指示哪些仓库下的模块是私有的,等于同时设置 GONOPROXY 和 GONOSUMDB。 |
安装过程:
#用 root 身份
yum install -y wget #安装 wget
#下载 go,版本号可以更新
wget https://go.dev/dl/go1.20.6.linux-amd64.tar.gz
#解压至/usr/local
tar -C /usr/local -zxvf go1.20.6.linux-amd64.tar.gz
#删除安装包
rm -f go1.20.6.linux-amd64.tar.gz
vi /etc/profile #用 vi 编辑 profile 文件
#按 i 在最后添加 export PATH=$PATH:/usr/local/go/bin
#按 ESC,输入符号:,再输入 wq 回车保存退出
source /etc/profile #加载配置
echo $PATH #确认已添加 PATH
su dev #切换开发者用户,dev 为远程开发用户
#设置 goproxy 为国内镜像
go env -w GOPROXY=https://goproxy.cn,direct
命令行工具
Go 命令行工具位于 /usr/local/go/bin/go。
常用命令:
命令 | 描述 |
go version | 查看 Go 版本。 |
go env | 查看 Go 环境变量。 |
go get | 下载依赖源码包,下载后位于 GOPATH/src 下。 |
go install | 编译并安装依赖包,安装后位于 GOPATH/bin 下。 |
go build | 编译源码,生成可执行文件。 |
go run | 运行源码文件,一般用来运行单个文件。 |
go fmt | 格式化源码。 |
go vet | 检查代码错误。 |
go test | 运行单元测试。 |
go generate | 运行代码生成工具。 |
go mod | 模块管理工具,用于下载、更新、删除依赖包。 |
开发工具
常用 vs code,安装 Go 相关插件,可以使用 remote ssh 插件进行远程开发。
基础知识
代码风格
Go 语言的代码风格类 C 语言,但更简洁。
主要区别点:
- 每一行代表一个语句结束,不需要分号;如果一行包含多个语句,需要加分号但不建议。
- 左花括号不另起一行。
- 使用 tab 缩进,go fmt 会自动格式化。
- 无冗余括号,for 和 if 表达式不需要括号。
- 无需显式声明变量类型,编译器自动推断。
- 支持多变量同时赋值,支持函数多返回值。
- switch 语句不需要 break,默认执行完 case 分支后自动 break。
主要相似点:
- 单行注释以 // 开头,多行注释以 /*开头,以*/ 结尾。
- 标识符由字母、数字、下划线组成,其中首个字符不能为数字,区分大小写。
- 运算符与运算符优先级类 c。
数据类型
- 布尔类型,bool,值为 true 或 false
- 数字类型,
- 整型,int8/int16/int32/int64,uint8/uint16/uint32/uint64,int/uint的长度取决于cpu。
- 字符,byte 是 uint8,rune(utf-8 字符) 是 int32。
- 指针,uintptr 是 uint。
- 浮点型,float32/float64
- 复数,complex64、complex128
- 字符串,string,底层为不可变的字节序列
- 复合类型,数组/slice/map/channel/struct/interface/函数
值类型与引用类型: 只有 slice、map、channel 、interface是引用类型,其他都是值类型。值类型如果要避免拷贝需要用指针。
变量
声明与赋值
Go 是静态强类型语言,变量类型在编译期确定,且会进行类型检查。 变量声明有多种方式,首选是忽略类型的极简方式。
//方式一:显示指定类型不赋值,会初始化为默认值
var a int
a = 10
//方式二:显示指定类型并赋值
var b int = 10
//方式三:直接赋值省略类型,编译器会自动推断类型
var b = 10
//方式四:直接赋值省略类型,编译器会自动推断类型,使用符号 := 替代 var 关键字
//注意:已声明过的变量再使用符号 := 会编译出错,只能声明局部变量
c := 10
多变量声明与赋值:
- 每种声明方式都多个变量声明,用逗号分隔,且类型可以不同。
- 可以用 var 加括号的方式进行批量声明,一般用于全局变量。
- 赋值时允许直接交换两变量的值,前提是类型相同。
- 用下划线 _ 忽略某个不需要的值。
//显示指定类型并赋值
var a, b int = 1, 2
//省略类型,可同时声明多种类型
x, s := 123, "str"
//批量声明
var(
data1 int
data2 string
)
//直接交换a和b的值
a, b = b, a
//假设 myfunc 返回两个值,第一个值不需要,用下划线忽略
_, ok := myfunc()
默认值
如果变量只声明未初始化,那么其值为默认值。各类型默认值如下:
- 布尔类型为 false
- 数字类型为 0
- 字符串为 "",不存在类似其他语言的空引用情况
- 其他为 nil
作用域
按优先级从高到低,作用域分为:
- 块作用域:在代码块内(花括号内或 if/for语句内)声明的变量作用域在代码块内。
- 函数作用域:在函数内声明的变量(包括参数和返回值),作用域在函数内。
- 全局作用域:在函数外声明的变量,作用域在整个包内或外部(需导入包)。
在同一个作用域下变量只能声明一次,但在不同作用域下变量可以同名,按所在作用域的优先级决定使用哪个。
类型转换
- 编译器会做类型检查,如果类型不匹配,编译器会报错。
- 数字类型转换,用 type(x) 的方式,浮点数转整型会丢失小数。
- int 与 int32 或 int64 类型不同,必须强制转换。
- 大整型转小整型超出范围不会报错,但会截断。
- 字节数组或字节转字符串 string(arrbyte)、string(ch)
- 字符串转字节数组 []byte(str)
- 字符串与数字类型的转换借助标准库strconv包,详见标准库字符串章节。
var a float64 = 511.678
var b int32 = int32(a) //浮点数转整型丢失小数
//var c int = b //int 与 int32 属于不同类型,编译报错
var c int = int(b) //强制转换
var d uint8 = uint8(b) //大整型转小整型超出范围不会报错,但会截断
fmt.Println(a, b, c, d) //511.678 511 511 255
arrByte := []byte("abc")
fmt.Println(arrByte) //[97 98 99]
arrByte[0] = 'A'
str := string(arrByte)
fmt.Println(str) //Abc
s1 := strconv.Itoa(c) //int 转 string
x, err := strconv.Atoi("123") //string 转 int,若成功err为nil
fmt.Println(s1, x, err) //511 123 <nil>
s2 := strconv.FormatFloat(a, 'f', 2, 64) //float 转 string,2位小数四舍五入
f, err := strconv.ParseFloat(s2, 64) //string 转 float
fmt.Println(s2, f, err) //511.68 511.68 <nil>
常量
声明与赋值
- 与变量声明类似,常量声明可以省略类型,也支持多常量声明。
- 常量必须在声明时赋值且不能再次赋值,可以用len(), cap(), unsafe.Sizeof()函数计算表达式的值。
- 常量可以批量声明与赋值,如果不赋值表示使用前面常量的初始化表达式。
//方式一:显示指定类型
const MAX, MIN int = 100, 1
//方式二:省略类型
const WIDTH, TEXT = 100, "abc"
//方式三:批量声明
const(
DATA = "abc"
DATA2 //使用前面常量的表达式,值也为"abc"
LEN = len(TEXT) //允许对前面的常量进行运算
)
枚举与 iota
- 常量可以用作枚举。
- 用 iota 常量计数器可以简化常量值定义,在 const 内部第一次出现时为 0,每增加 1 行(非空行)加 1。
const(
Known = 0
Male = 1
Female =2
)
const (
a = iota //0
b //1
c //2
d = "ha" //独立值,iota += 1
e //"ha" iota += 1
f = 100 //iota +=1
g //100 iota +=1
h = iota //7,恢复计数
i //8
)
数字的进制表示
数字常量支持多进制表达:
进制 | 表达方式 | 示例 |
十进制 | 常规写法 | 123 |
八进制 | 0开头 | 0123 |
十六进制 | 0x开头 | 0x123 |
二进制 | 0b开头 | 0b10101 |
字符串常量
- 字符串常量用双引号括起来,支持转义字符。
- \n 换行
- \t 制表符
- \' 单引号
- \" 双引号
- \\ 反斜杠
- 字符常量用单引号括起来。
- 支持多行字符串,用符号`str`(区别于单引号和双引号)。
运算符
类型 | 运算符 |
算术 | +加 -减 *乘 /除 %取余 ++自增 --自减 |
关系 | ==等于 !=不等于 >大于 <小于 >=大于等于 <=小于等于 |
逻辑 | &&与 ||或 !非 |
位 | &位与 |位或 ^位异或 <<左移 >>右移 |
赋值 | =赋值 +=相加赋值 -=相减赋值 *=等 |
字符串 | +拼接 +=拼接赋值 ==等于 !=不等于 |
其他 | &指针取地址 *指针取值 |
注意:
- 区别于其他语言,++和--只能在变量后面作为语句,不能在表达式中使用。
- 字符串也支持>、>=、<、<=关系运算符,作用是逐字符比较。
条件控制
if 条件
- 条件表达式不需要加括号,且左花括号不另起一行。
- 支持在表达式前加执行语句(如声明变量),使代码保持简洁。
- 支持短路求值,即如果第一个条件表达式为 false,则不再计算第二个。
- 支持嵌套。
if a > 2 {
//TODO
} else if a > 3 {
//TODO
} else {
//TODO
}
//在表达式前使用赋值语句,ok 仅在 if 块内有效
if ok := isOk(); ok {
//TODO
}
switch 条件
- 同 if,条件表达式不需要加括号,且左花括号不另起一行。
- 同 if,支持在表达式前加执行语句(如声明变量),使代码保持简洁。
- case 后不需要 break,执行完 case 后自动 break。
- 如果执行完 case 后不要自动 break,需使用fallthrough。
- case 后的表达式可以包含多个,用逗号隔开。
- switch 后可以没有条件,通过 case 后加条件表达式来判断。
- switch 可以用于判断某个 interface 变量的实际类型,结合 x.(type) 表达式使用,该表达式只能用于 switch。
switch num:=myfunc(); num {
case 1: //TODO
case 2: //TODO
case 3, 4, 5 : //TODO
default: //TODO
}
switch {
case score == 100, score == 99: //TODO
case score >= 90: //TODO
case score >= 60: //TODO
default: //TODO
}
switch x.(type) { //假设 x 是 interface{} 类型
case nil:
fmt.Printf("x 是 nil")
case int:
fmt.Printf("x 是 int")
case float64:
fmt.Printf("x 是 float64")
}
select 条件
- select 提供语言层面的多路复用机制。
- 只能作用于通道,case 后必须是通道操作。
- switch 会监听所有通道,哪个通道可以执行则执行,其他忽略。
- 如果有多个通道可以执行,则随机公平选取一个执行。
- 如果没有通道可以进行,则执行 default 语句,如没有 default 则阻塞。
select {
case v := <-ch1: //如果ch1有数据 则执行
fmt.Print(v, " ")
case v := <-ch2: //如果ch2有数据 则执行
fmt.Print(v, " ")
default://如果 ch1 和 ch2 都没数据则执行
}
循环控制
Go 语言的循环控制都是用 for 关键字,有以下多种形式:
- for init; condition; post { }
- for condition { },类似其他语言的 while(condition) 循环。
- for { },类似其他语言的 while(true) 循环。
- for range {},类似其他语言的 foreach,用于迭代集合。
另外,循环中可以使用 break/continue/goto+label语句退出循环,用法类似其他语言。
for i := 0; i < 10; i++ {
//TODO
}
for i < 100 {
i++
}
for {
//TODO
}
for k, v := range map {
//TODO
}
函数
定义与使用
Go 语言的函数定义语法如下:
func functionName(param1 type1, param2 type2, ...) (result1 type1, result2 type2, ...) {
//TODO
return result1, result2, ...
}
函数名特点:
- 函数名以大写字母开头,是公开函数,表示允许被其他包调用。
- 函数名以小写字母开头,是内部函数,仅限包内使用。
- 不支持函数重载(相同函数名使用不同参数类型)。
参数特点:
- 支持多个参数,或无参数。
- 一组类型相同的参数时,可以简写参数类型。
- 支持可变参数,用符号...表示参数个数不确定,其实际类型是切片。
- 值类型作为参数时,会发生值拷贝,如果要使用引用传递,需用指针。
- 函数本身也可以作为参数。
func func1(){} //无参数
func func2(s string, x, y int){} //多个参数,x与y都为int类型,简写
func func3(args ...int){} //可变参数,调用时用 func3(1,2,3) 或 func3(slice...)
func func4(a *int){} //用指针实现引用传递
func func5(a func(int)){} //函数本身作为参数
返回值特点:
- 支持多个返回值,或无返回值,多个返回值时需用括号。
- 使用命名返回值时,返回值在函数中赋值,且return 语句可以不带返回值。
- 命名返回值,如果是一组类型相同的返回值时,可以简写。
- 函数本身也可以作为返回值。
- 函数调用时,可以用 _ 忽略某个返回值。
func func1() int { return 0 } //单返回值
func func2() (int, string) { //多返回值
return 0, "" //必须带返回值
}
func func3() (x, y int, s string) {//多命名返回值,简写
x, y, s = 0, 1, ""
return //等同于 return x, y, s
}
func buildFunc() func(string) { //函数本身作为返回值
return func(s string) {
fmt.Println(s)
}
}
//调用方法如:buildFunc()("hello")
特殊函数
init()
- 在包初始化时执行,允许定义多个,都会被执行。
- 不能带参数和返回值。
- 用 import _ 引用一个包,就是为了执行该包的 init 函数。
main()
- 只能在main包中定义一个。
- 不能带参数和返回值。
- 在本包和依赖包的所有 init() 函数执行完后才执行。
匿名函数
匿名函数是没有函数名的函数,应用场景:
- 赋值给变量、作为参数传递或作为函数返回值。
- 创建闭包。
func main(){
//函数变量
myfunc := func (s string){
fmt.Println(s)
}
myfunc("hello")
//并发执行
go func (s string){
fmt.Println(s)
}("hello")
}
闭包
- Go 支持在函数体内部定义函数,内部函数可以访问外部函数的局部变量。
- 内部函数与其外部环境变量的组合体就是闭包。
- 即使外部函数已经执行完了,其作用域的变量仍然作为闭包的一部分保留下来,可以延续访问。
- 闭包的使用场景:
- 延迟执行,通过 defer 关键字运行一个匿名函数,处理资源释放。
- 并发执行,通过 go 关键字运行一个匿名函数,函数内可以访问外部变量。
- 事件回调,当事件发生时就可以访问到所在环境的变量。
- 缓存计算结果。
func outer() func() int {
counter := 0
return func() int {
counter++
return counter
}
}
func main() {
//闭包
closure := outer()
fmt.Println(closure()) //1
fmt.Println(closure()) //2
}
//该例子中,outer()函数执行完后,counter局部变量作为闭包的一部分保留下来,仍然可以被读写。
递归
Go 支持递归,递归函数是指函数在内部直接或间接调用自身。 递归函数的特性:
- 函数内部调用自身。
- 函数内部必须要有退出条件,否则会陷入死循环。
defer 延迟执行
defer 语句用于延迟调用指定的函数。 defer 的特点:
- defer 语句的执行顺序与声明顺序相反。
- defer 是在返回值确定与 return 之间执行的。
defer 的使用场景:
- 释放资源,如打开的文件、数据库连接、网络连接等。
- 捕获panic,在发生异常时,defer语句可以捕获异常,并执行defer语句后的函数。
//文件释放
func openFile() {
file, err := os.Open("txt")
if err != nil {
return
}
defer file.Close() //合理位置
}
//锁释放
func lockScene() {
var mutex sync.Mutex
mutex.Lock()
defer mutex.Unlock()
//业务代码...
}
//捕获 panic
func demo() {
defer func() {
if err := recover(); err !=nil{
fmt.Println(string(Stack()))
}
}()
panic("unknown")
}
复杂结构
struct 结构体
struct 是自定义结构体,用于聚合多种类型的数据。
struct 的定义与使用
定义:
- 结构体的类型名在包内唯一。
- 字段名必须唯一。
- 同类型的字段可以简写在一行。
- 支持匿名结构体,用于临时使用。
- 支持嵌套结构体。
- 支持字段加 tag,再通过反射来获取,常用于序列化或 orm。
使用:
- 结构体是一种类型,像其他类型一样声明与实例化
- 初始化时可以直接对成员赋值,可以用字段名,也可以直接按字段顺序赋值。
- 结构体是值类型,会发生值拷贝。
- 支持用 new(T) 创建结构体指针。
- 无论实体还是指针,都用符号.访问其字段。
type Point struct{ X, Y int } //X 与 Y 简写在一行
type Staff struct {
Id int `json:"Identity"` //加 tag 控制 json 序列化字段名
Name string
Address struct { //嵌套匿名结构体
Street string
City string
}
}
func main() {
p1 := Point{1, 2} //按字段顺序直接赋值
p2 := Point{X: 3, Y: 4} //按字段名赋值
fmt.Println(p1, p2) //{1 2} {3 4}
s := &Staff{ //获取指针,经逃逸分析会分配到堆
Name: "wills",
Address: struct {
Street string
City string
}{
Street: "123 St.",
City: "SHENZHEN",
},
}
s.Id = 1 //通过指针访问字段方式一样
data, _ := json.Marshal(s)
fmt.Println(string(data))
//{"Identity":1,"Name":"wills","Address":{"Street":"123 St.","City":"SHENZHEN"}}
}
struct 方法
Go 支持为 struct 定义方法,再通过 x.方法名() 的方式调用。 方法定义方式如下:
func (x T) 方法名(参数) (返回值) { //对类型 T 定义方法
}
func (x *T) 方法名(参数) (返回值) {//对类型 T 的指针定义方法
}
注意:
- 方法可以定义在类型或类型的指针上,两种方式都可以通过 x.方法名() 的方式调用。
- 定义在指针上时,方法体中可以修改实例的成员变量。
- 定义在类型上时,修改实例的成员变量会因为值拷贝而失效。
- 不能同时定义在指针和类型上,否则会编译失败。
type Point struct{ X, Y int }
func (p *Point) Add1() { p.X++; p.Y++ }
func (p Point) Add2() { p.X++; p.Y++ } //因为值拷贝修改无效
func main() {
p := Point{10, 20} //按字段顺序直接赋值
p.Add1() //p 的数据发生变更
fmt.Println(p) //{11 21}
p.Add2() //p 的数据不会发生变更
fmt.Println(p) //{11 21}
}
struct 嵌入
struct嵌入其他命名struct可以实现组合模式,嵌入其他匿名struct可以实现类似继承模式。 如果A嵌入了匿名的B和C,则可以通过A直接访问B和C的字段或方法,Go 会由浅至深地查找,找到则停止查找。
type B struct{ x, y int }
type C struct{ m, n int }
func (b *B) Add() { b.x++; b.y++ }
type A struct {//A嵌入匿名的 B 和 C
B
C
z int
}
func main() {
a := A{B{10, 11}, C{20, 21}, 30}
a.Add() //通过 A 直接访问 B 的方法
a.m = 25 //通过 A 直接访问 C 的字段
fmt.Println(a) //{{11 12} {25 21} 30}
}
指针
指针是用来保存变量内存地址的变量。有以下特点:
- 用 & 取地址,用 * 取值。
- 用 new 实现堆分配并创建指针。
- 数组名不是首元素指针。
- 指针不支持运算。
- 可用 unsafe 包打破安全机制来操控指针。
Go指针的应用场景:
- 使用指针实现作为参数,实现引用传递。
- 使用指针实现返回值,避免大对象的值拷贝,会引发逃逸分析,可能改堆分配。
- 使用指针实现方法,实现对成员变量的修改。
- 实现链表、树等数据结构。
逃逸分析:
- 逃逸分析是指在编译期分析代码,决定是否需要将变量从栈分配改到堆分配。
- 指针和闭包都会引发逃逸分析。
- 使用命令输出分析结果:go build -gcflags '-m -l' x.go
//以下例子目的在展示指针用法,不代表该场景下需用指针。
//小对象建议使用值传递和值返回,避免在堆上分配内存,因为堆分配开销较大,还需要通过 GC 回收内存。
type Point struct{ x, y int }
// 使用指针作为参数,实现引用传递。
// 使用指针实现方法,实现对成员变量的修改。
func (its *Point) Add(p *Point) {
its.x, its.y = its.x+p.x, its.y+p.y
}
// 使用指针作为返回值,会引发逃逸分析,返回值在堆上分配。
func buildPoint(x, y int) *Point {
return &Point{x, y}
}
func main() {
p := buildPoint(1, 2)
p.Add(&Point{3, 4})
fmt.Println(p) //&{4 6}
}
数组
数组是定长且有序的相同类型元素的集合。有以下特点:
- 数组的长度是数组类型的一部分,因此不同长度的数组是不同的类型。
- 数组在声明赋值时,可以用符号...借助编译器推断长度。
- 初始化时可以指定索引来初始化。
- 数组是值类型,赋值或传参时会发生值拷贝,要使用引用拷贝需用指针。
- 使用内建函数len()和cap()获取到的都是数组长度。
- 数组可以用 for range 来遍历,支持
- for i,v := range arr {} //i为索引、v为元素
- for i := range arr {} //i为索引
- for _,v := range arr {} //v为元素
- 支持多维数组,本质是数组的数组。
//方式一,先声明再赋值
var a [3]int
a = [3]int{1,2,3}
//方式二,用 var 声明且赋值
var b = [3]int{1, 2, 3}
//方式三,用 := 符号声明且赋值
c := [3]int{1, 2, 3}
//方式四,借助编译器推断长度
d := [...]int{1, 2, 3}
s := [...]string{0: "a", 3: "b"} //通过索引赋值,1 和 2 是默认值""
for index, val := range s { //index是索引,val 是元素值
if val == "" {
s[index] = "-" //注意 val 值复制修改无效,要通过索引修改数组
}
}
fmt.Println(len(s), s) //4 [a - - b]
//多维数组
arr := [2][3]int{{11, 12, 13}, {21, 22, 23}}
fmt.Println(arr) //[[11 12 13] [21 22 23]]
fmt.Println(len(arr)) //2
切片
切片是动态数组,是变长且有序的相同类型元素的集合。
切片的使用:
- 切片的声明与初始化与数组相似,但是不需要指定长度。
- 用 len()获取长度,用 cap()获取容量。
- 如果未初始化,值为 nil,长度为 0,容量为 0。
- 用 append() 函数可以动态的添加元素,添加元素可能导致切片扩容。
- 用 make() 函数初始化切片,可以指定长度和容量。
- 切片是引用类型,赋值或传参时仅仅是复制引用。
- 要复制创建新切片需用 make()初始化新切片再用copy()复制数据。
- 用[上限:下限]语法可以截取子切片,包括上限但不包括下限,不指定上限或下限表示截取到头或尾。
- 切片可以用 for range 来遍历,类似数组。
- 支持多维切片,本质是切片的切片。
s1 := []int{0, 1, 2} //声明且初始化
s1 = append(s1, 3) //追加元素,append返回值必须赋值回切片
s2 := s1 //仅复制引用
s2[0] = 9 //s2和s1是同个切片的引用,修改s2也会修改到s1
fmt.Println("s1:", len(s1), cap(s1), s1) //s1: 4 6 [9 1 2 3]
var s3 []int //仅声明不初始化
fmt.Println("s3:", len(s3), cap(s3), s3 == nil) //s3: 0 0 true
s3 = []int{} //初始化空切片,空切片不等于 nil
fmt.Println("s3:", len(s3), cap(s3), s3 == nil) //s3: 0 0 false
s3 = make([]int, len(s1), 100) //初始化容量为 100
copy(s3, s1) //复制数据
s4 := append(s3, 4) //追加到新的切片,没有扩容 s4 和 s3 底层数组为同一个,但长度不同表示的数据仍然不同
s4[0] = 99 //会同时修改到s3和s4的第一个元素
fmt.Println("s3:", len(s3), cap(s3), s3) //s3: 4 100 [99 1 2 3]
fmt.Println("s4:", len(s4), cap(s4), s4) //s4: 5 100 [99 1 2 3 4]
s5 := s4[1:3] //截取索引1到2,不包括 3
fmt.Println("s5:", len(s5), cap(s5), s5) //s5: 2 99 [1 2]
s6 := s4[:3] //截取索引0到2,不包括 3
fmt.Println("s6:", len(s6), cap(s6), s6) //s6: 3 100 [99 1 2]
s7 := s4[3:] //截取索引3到尾部
fmt.Println("s7:", len(s7), cap(s7), s7) //s7: 2 97 [3 4]
s7[0] = 1000 //截取的子切片数据仍然在母切片上,故修改元素会修改到母切片
fmt.Println("s4:", len(s4), cap(s4), s4) //s4: 5 100 [99 1 2 1000 4]
map
map 是一种无序的键值对的集合,键是唯一的。
map 的使用:
- 声明时需要指定 key 和 value 的类型,可以同时做初始化。
- 用 make() 或直接赋值做初始化。
- 未初始化时,值为 nil,长度为0,无法使用,否则会panic。
- 用 len() 获取长度,没有容量不支持 cap()。
- 如果预估数据较多,make() 时可以指定 size,避免扩容。
- 通过 v,ok := m[k] 方式获取 key 对应的 value,ok 表示是否找到。
- 是引用类型,赋值或传参时仅仅是复制引用。
- 不支持用 copy() 复制数据,需遍历逐key复制。
- 可以用 for range 来遍历。
- for k,v := range m {} //k为键、v为值
- for k := range m {} //k为键
- for _,v := range m {} //v为值
- 元素是无序的,无法保证每次遍历 key 的顺序都是一样的。
- 支持用 delete() 删除某个 key,且可以在遍历中删除。
- 支持多层嵌套,本质是map的map。
- map 不是并发安全的,需用锁或 sync.Map。
var m1 map[string]int //只声明不初始化无法使用
// m1["a"] = 1 //panic
fmt.Println("m1,", len(m1), m1 == nil) //m1, 0 true
m1 = map[string]int{} //初始化为空则可以使用
fmt.Println("m1,", len(m1), m1 == nil) //m1, 0 false
m2 := make(map[string]int, 100) //用make初始化,设置初始大小 100
fmt.Println("m2,", len(m2), m2) //m2, 0 map[]
m3 := map[string]int{"a": 1, "b": 2} //直接赋值初始化
fmt.Println("m3,", len(m3), m3) //m3, 2 map[a:1 b:2]
m4 := m3 //仅复制引用
m4["c"] = 3 //m4和m3是同个map的引用,修改m4也会修改到m3
fmt.Println("m3,", len(m3), m3) //m3, 3 map[a:1 b:2 c:3]
for k := range m4 { //遍历key
if k == "b" {
delete(m4, k) //遍历中可以删除 key
}
}
_, ok := m4["b"] //ok表示 key 是否存在
fmt.Println("m4, b ok", ok) //m4, b ok false
mm := map[string]map[string]int{ //嵌套 map
"一": {"a": 10, "b": 11},
"二": {"m": 20, "n": 21},
}
fmt.Println("mm,", len(mm), mm) //mm, 2 map[一:map[a:10 b:11] 二:map[m:20 n:21]]
interfae 接口
interfae 用于定义一组方法,只要结构体实现了这些方法,就实现了该接口。接口的作用在于解耦和实现多态。 接口可以嵌套多个其他接口,等于拥有了这些接口的特征。 空接口 interface{}(内建别名 any) 可以赋值为任意类型变量,结合类型判断或反射可以实现处理任意类型数据。 接口类型转换可以用类型断言,语法如 x,ok := value.(Type)。 接口类型的变量可以用符号==进行比较,只有都为 nil 或类型相同且值相等时才为 true。
type Phone interface {
Call(num string)
}
type Camera interface {
TakePhoto()
}
type SmartPhone interface { //嵌套了 Phone 和 Camera
Phone
Camera
}
type IPhone struct{}
func (iphone IPhone) Call(num string) {
fmt.Println("iphone call", num)
}
func (iphone IPhone) TakePhoto() {
fmt.Println("iphone take photo")
}
type Android struct{}
func (android Android) Call(num string) {
fmt.Println("android call", num)
}
func (android Android) TakePhoto() {
fmt.Println("android take photo")
}
type SmartPhoneFactory struct{}
func (factory SmartPhoneFactory) CreatePhone(phoneType string) SmartPhone {
switch phoneType {
case "iphone":
return IPhone{}
case "android":
return Android{}
default:
return nil
}
}
func main() {
sp := SmartPhoneFactory{}.CreatePhone("iphone")
sp.Call("123456") //iphone call 123456
sp.TakePhoto() //iphone take photo
var x interface{} = sp
switch x.(type) {
case IPhone:
fmt.Println("x is iphone")
case Android:
fmt.Println("x is android")
} //x is iphone
iphone, ok := x.(IPhone) //类型断言
fmt.Println(iphone, ok) //{} true
var value interface{} = 123
i, ok := value.(int)
fmt.Println(i, ok) //123 true
i32, ok := value.(int32) //常量 123 是 int 类型,类型断言失败
fmt.Println(i32, ok) //0 false
}
并发
背景知识
- 串行、并行与并发的区别:
- 串行是指多个任务按照时间先后由一个处理器逐个执行。
- 并行是指多个任务在同一时间由多个处理器同时执行。
- 并发是指多个任务在宏观上并行执行,但是在微观上只是分成很多个微小指令串行或并行执行。
- 进程:操作系统分配系统资源(cpu 时间片、内存)的最小单位。
- 线程:操作系统调度的最小单位,同进程内的不同线程除了拥有独立的栈外,其他资源都共享。
- 协程:轻量级线程,不依赖操作系统调度,开销小(线程栈8M,协程栈2k 动态增长)。
- Go 并发:通过协程 goroutine 实现并发,通过通道 channel 实现同步。
协程
goroutine 是一种语言级的协程,是 go 并发调度的单元。特点如下:
- 协程调度由运行时负责,编码时不需要关注其调度。
- 切换调度不依赖系统内核线程,开销小,数量不受限。
- 可以用 go 加函数调用创建协程。
- 可以用 go 加匿名函数创建协程,会创建闭包,函数内可以访问外部变量。
- 程序启动时会创建主协程,调用main(),当main()结束时,其他协程停止运行。
- 协程的运行是没有严格先后顺序的,由运行时调度。
func doJob(name string) string {
fmt.Println("doJob:", name)
return name + "_result"
}
func main() {
go doJob("job1") //用 go 调用函数启动协程
x := "nothing"
go func() {
x = doJob("job2") //通过闭包修改外部环境变量 x
}()
fmt.Println("x:", x) //x: nothing,协程创建了但未运行
time.Sleep(3 * time.Second) //简单等待协程运行,更科学的做法是用线程同步机制
fmt.Println("x:", x) //x: job2_result,协程已运行
}
通道
channel 是用于协程间传递指定类型数据的通道,是一种队列,可以实现协程并发同步。使用要点:
- 声明通道时需指定数据类型,方式如 var ch chan string。
- 通道是引用类型,赋值或传参时仅仅是复制引用。
- 初始化通道:
- 用 make() 初始化,可以同时指定缓冲区容量,未指定时表示没有缓冲区。
- 如果未初始化,通道为 nil,长度为0,容量为0。
- 用 len() 获取长度,表示缓冲区数据的实际数量。
- 用 cap() 获取容量,容量在初始化后就不会变化。
- 如果未初始化,对通道发送或接收不会 panic,但会阻塞等待其他协程初始化。
- 关闭通道:
- 用 close() 关闭通道。
- 通道关闭后再关闭将 panic。
- 关闭通道的原则:只允许发送端关闭通道,接收端不需要。有多个发送端时也不要关闭通道。
- 向通道发送数据:
- 用 ch <- x 方式发送数据。
- 对于没有缓冲区的通道,发送时如果没有被接收将阻塞等待。
- 对于有缓冲区的通道,只有缓冲区满了发送端才阻塞等待。
- 对于已关闭的通道,再发送会 panic。
- 从通道接收数据:
- 用 x := <-ch 方式接收数据,x 为数据。
- 用 x,ok := <-ch 方式接收数据,如果通道关闭则 ok 为 false。
- 如果接收端接收不到数据,会阻塞等待。
- 对于已关闭的通道,仍然可以接收数据,接收完剩余数据后不阻塞。
- 遍历通道
- 支持 for range 遍历,如 for x := range ch {}
- 如果没有数据,遍历会阻塞等待。
- 如果通道关闭,遍历完数据后会退出。
- 只读/只写通道
- 通常只是作为函数参数或返回值,借助编译器限制对某个通道的只读或只写。
- 函数参数为只读/只写通道时,调用方可以传递正常通道。
- 可以关闭只写通道,不能关闭只读通道。
func doJob(name string, ch chan string) { //通道作为参数引用传递
fmt.Println("doJob:", name)
ch <- name + "_result" //将处理结果发送到通道
close(ch) //关闭通道
}
func main() {
var ch chan string //仅声明不初始化
// fmt.Println(<-ch) //不初始化也可以接收,但会阻塞等待,这里会导致死锁异常。
fmt.Println(len(ch), cap(ch), ch == nil) //0 0 true
ch = make(chan string) //初始化,没有缓冲区
fmt.Println(len(ch), cap(ch), ch == nil) //0 0 false
go doJob("job1", ch) //启动协程
fmt.Println(len(ch), cap(ch)) //0 0,对于没有缓冲区的通道,长度任何时候都是 0
data, ok := <-ch //接收到数据则 ok 为 true
fmt.Println(data, ok) //job1_result true
data, ok = <-ch //再接收会阻塞,直到通道关闭
fmt.Println(data == "", ok) //true false
ch2 := make(chan string, 2) //声明且初始化,缓冲区容量
go func() {
for _, a := range "abcd" {
ch2 <- string(a)
fmt.Printf("w(%c,%d) ", a, len(ch2)) //写入完成后输出
}
time.Sleep(3 * time.Second) //等待3秒
close(ch2) //关闭通道
}()
for x := range ch2 { //遍历通道,没有数据会阻塞,等通道关闭后退出遍历
fmt.Printf("r(%s,%d) ", x, len(ch2))
}
// w(a,0) w(b,1) w(c,2) r(a,2) r(b,2) r(c,1) r(d,0) w(d,0)
}
func ReadOnly(ch <-chan int) {
for x := range ch {
print(x, " ")
}
}
func WriteOnly(ch chan<- int) {
for i := 0; i < 10; i++ {
ch <- i
}
close(ch)
}
func main() {
ch := make(chan int)
go WriteOnly(ch)
ReadOnly(ch)
}
错误处理
区分错误与异常
- 在 Go 语言中,错误与异常是不同概念,用不同方式处理。
- 错误是指可能出现问题的地方出现了问题,是在意料之中的,是业务的一部分。
- 异常是指不应该出现问题的地方出现了问题,是意料之外的,与业务无关。
- 错误通过 error 接口机制来处理,异常通过 panic 机制处理。
error
- Go 提供了内建的错误接口 error,仅包含一个Error()字符串的方法。
- 任何实现了error接口的类型都可以作为错误使用.
- 可以断言底层结构类型,并通过底层类型的字段或方法获取更多错误信息。
- 可以通过errors包的New()函数或fmt包的Errorf()函数创建简单的自定义错误。
- 可以通过github.com/pkg/errors包进行错误处理,在标准errors包基础上增加堆栈跟踪功能。
- 使用错误注意事项:
- 没有失败时不使用 error。
- 当失败原因只有一个时,返回布尔值而不是 error。
- error 应放在返回值的最后。
- 错误最好统一定义和管理,避免散落到代码各处。
- 错误应包含足够的信息,必要时使用自定义结构,或增加堆栈信息。
//内建error接口
type error interface {
Error() string
}
//断言底层结构类型,并获取更多错误信息。
func main() {
f, err := os.Open("/test.txt")
if err, ok := err.(*os.PathError); ok {
fmt.Println("File at path", err.Path, "failed to open")
return
}
fmt.Println(f.Name(), "opened successfully")
}
package main
import (
"fmt"
"github.com/pkg/errors"
)
// 自定义error
type BizError struct {
Code int32 //错误编码
Message string //错误信息
Cause error //内部错误
}
// 实现error接口
func (err *BizError) Error() string {
return fmt.Sprintf("%s", err)
}
// 实现fmt.Formatter接口
func (err *BizError) Format(s fmt.State, verb rune) {
switch verb {
case 'v':
if s.Flag('+') {
fmt.Fprintf(s, "code:%d, message:%s", err.Code, err.Message)
if err.Cause != nil {
fmt.Fprintf(s, ", cause:%+v", err.Cause)
}
return
}
fallthrough
case 's':
fmt.Fprint(s, err.Message)
}
}
func WrapBizError(code int32, cause error) error {
return &BizError{
Code: code,
Message: mapBizErrorMessage[code],
Cause: cause,
}
}
const ERROR_LOGIN_FAIL = 1000
const ERROR_LOGIN_FAIL_MSG = "login fail"
var mapBizErrorMessage = map[int32]string{
ERROR_LOGIN_FAIL: ERROR_LOGIN_FAIL_MSG,
}
func login(user string, pwd string) error {
//github.com/pkg/errors包的Errorf()创建的错误包含堆栈信息
return WrapBizError(ERROR_LOGIN_FAIL, errors.Errorf("user '%s' not found", user))
}
func main() {
err := login("wills", "123456")
if err != nil {
fmt.Printf("%+v", err)
}
}
panic
- panic 机制类似于其他语言的 try{} catch{} finally{}。
- 通过内建函数 panic() 抛出异常,参数可以是任何类型的变量。
- 在 defer 中通过内建函数 recover() 捕获异常。
- recover() 返回值是 panic() 抛出的数据。
- 如果 panic 没有被捕获,会向上一层函数抛出,直到当前协程的起点,然后终止其他所有协程(包括主协程)。
- 使用 panic 注意事项:
- 在开发阶段,panic() 中断程序以便尽快发现并修复缺陷。
- 在部署阶段,需要选择一个合适的上游进行 recover() 避免程序退出。
- 对于入参不应该有问题的函数,使用 panic,比如 regexp.MustCompile() 的实现。
- 对于不应该出现的分支,使用 panic。
func divide(a, b int) int {
if b == 0 {
panic("除数不能为零")
}
return a / b
}
func main() {
defer func() {
if err := recover(); err != nil {
fmt.Println("panic:", err)
debug.PrintStack() //堆栈信息
}
}()
result := divide(10, 0)
fmt.Println(result)
}
依赖管理
Go 通过包(package)和模块(module)进行代码的模块化组织和管理。
包
- 包(pakage)是同一目录中一起编译的文件集合。
- 包的类型:
- 标准库包:由 Go 官方提供的包。
- 第三方包:由第三方提供的包,如 github.com 发布的包。
- 内部包:项目内部的包。
- 包的定义:
- 同个目录下源码文件的非注释第一行,用 package 定义包名。
- 包名一般与目录名相同,如不同,在 import 时需要指定包名。
- 包名不能包含“-”符号。
- 包内可以定义多个 init()函数,在导入时会被执行。
- main 包是程序入口包,必须定义一个 main 函数作为入口函数,编译后会生成可执行文件。
- 包的使用:
- 通过 import 关键字引入包。
- 对于标准库包,直接使用包名。
- 对于第三方包,需使用”模块名/包名“。
- 对于内部包,如果启用了GO111MODULE,则需要使用”模块名/包名“。
- 对于内部包,如果未启用GO111MODULE,则需要使用包的路径,如”./pkg/mypkg“。
- 在代码中通过包名前缀引用外部包的函数、类型、变量、常量,只有首字母大写的标识符才能引用。
- import 时可以指定包别名,引用时用别名前缀。
- 只导入不使用的包,只执行其 init()函数,可使用“_”忽略。
/* 示例为未启用GO111MODULE的情况,项目文件结构如下:
.
|-- main.go
`-- mypkg
`-- mypkg.go
*/
//mypkg/mypkg.go
package mypkg
import "fmt"
func init() {
fmt.Print("init ")
}
func MyFunc() {
fmt.Println("MyFunc ")
}
//main.go
package main
import p "./mypkg"
func main() {
p.MyFunc()
}
//运行输出:init MyFunc
模块
- 模块化管理:
- 模块化管理是 go1.11版本起引入的特性。
- 将项目代码模块化,可以更好地组织依赖和版本控制。
- 通过环境变量GO111MODULE 控制是否启用,值 on/off/auto,auto 表示根据目录情况决定是否启用,go1.16之后默认为 on。
- 模块:
- 模块是一个项目代码库,是版本控制的单元,是包的集合。
- 模块根目录下包含 go.mod 和 go.sum 文件.
- 模块版本号是通过 git tag 来实现的。
- go.mod 文件:
- 包含模块的元数据,如模块名、依赖的模块及版本等。
- 可以用 go mod 命令进行管理。
- go mod init,把当前目录初始化为新模块,会创建go.mod文件。
- go mod download,下载 go.mod 下所有依赖的模块。
- go mod tidy,整理依赖关系,添加丢失,移除无用。
- go mod vendor,将依赖复制到vendor目录,在编译时无需下载。
- go mod graph,查看模块依赖图。
- go mod edit -fmt,格式化 go.mod文件。
- go mod edit -require=xxx@v.1,添加一个依赖。
- go mod edit -droprequire=xxx,删除一个依赖。
- go mod edit -replace=xxx@v.1=xxx@v.2,替换一个依赖,如开发期替换成本地路径。
- go mod edit -exclude=xxx,添加一个排除依赖。
- go mod edit -dropexclude=xxx,删除一个排除依赖。
- go get xxx,可以下载 xxx 模块的最新版本,并更新当前目录的 go.mod文件。
- go.sum 文件:
- 自动生成,包含依赖模块的校验和,用于防篡改。
- 每行由模块名、版本、哈希算法、哈希值组成。
- 构建时会计算本地依赖包的哈希值与 sum 文件是否一致,不一致则构建失败。
//示例 go.mod 文件,仅包含一个依赖
module code.oa.com/mymod //模块名,需包含代码库地址
go 1.20 //指明本模块代码所需的最低 go 版本,仅起标识作用
require github.com/pkg/errors v0.9.1 //依赖的模块名及版本
//示例 go.sum 文件,仅包含一个依赖
github.com/pkg/errors v0.9.1 h1:FEBLx1zS214owpjy7qsBeixbURkuhQAwrK5UwLGTwt4=
github.com/pkg/errors v0.9.1/go.mod h1:bwawxfHBFNV+L2hUp1rHADufV3IMtnDRdf1r5NINEl0=
依赖版本
- 模块的版本号为仓库的 tag 号,需遵循以下规范:
- 格式:v主版本号.次版本号.修订号-预发布号
- 主版本号:递增表示出现不兼容的 API变化。
- 次版本号:递增表示增加新的功能,但不影响 API 兼容性。
- 修订号:递增表示修复 bug,也不影响 API 兼容性。
- 预发布号:用于标识非稳定版本,如 alpha(内测)、beta(公测)、rc(发布候选)等。
- v0主版本:可以在生产环境使用,但不保证稳定性和向后兼容性。
- go get 时会获取仓库的最新 tag 作为模块版本。
- 如果仓库没有 tag,会生成伪版本号,格式:v0.0.0-最新commit时间-commit哈希
底层原理
切片实现原理
- 切片由数组指针、长度和容量组成,底层数组分配在堆上。
- 不同切片可以共用一个底层数组,只要指针、长度和容量不同,切片表达的数据就不同。
- 截取操作的结果会创建新切片,但是底层数组不变。
- 追加操作的结果会创建新切片,如果容量够底层数组也不变,否则会分配容量更大的底层数组,即扩容。
- 新容量由扩容因子决定,不同版本的 Go 扩容策略不同:
- Go 1.8 之前:当旧容量小于 1024 时,扩容因子为 2 倍,否则为 1.25。
- Go 1.8 及之后:策略稍微改进,在 旧容量小于等于 256时,扩容因子 2 倍,后面会逐步减小到 1.25。
type slice struct {
array unsafe.Pointer // 指向底层数组
len int // 长度
cap int // 容量
}
map 实现原理
map 的数据结构,核心是哈希表+桶链,具体如下:
- map 是一个指针,指向一个哈希表 hmap。
- 哈希表包含一个桶数组,长度是2的B次方。
- 桶是固定长度结构,包括最多8个键值对和键哈希值高8位。
- key的哈希值低B位决定存储在哪个桶,桶内则顺序存储。
- 桶内存储超过8个时,链接到溢出桶存储。
- 装载因子(键数/桶数)达到 6.5 时增量扩容,溢出桶过多时触发等量扩容。
map 的算法
- 查找
- 用 key 和哈希种子(map 创建时生成)计算哈希值(64 位)。
- 取哈希值低位(长度B)对应桶索引,
- 取哈希值高 8 位在桶内遍历topbits地址表,查找key的位置。
- 找到key位置后,进一步比较key是否相等,如果不等则继续遍历。
- 如果桶内找不到,则通过桶链继续查找溢出桶。
- 如果遍历完找不到 key,则返回value类型的默认值。
- 插入/更新
- 同查找过程,尝试找到 key 位置,如果找到,则更新 value。
- 如果找不到,且遍历过程找到了空位,则插进空位。
- 如果没有空位,则判断是否要扩容。
- 如果不需要扩容,则生成一个溢出桶,将元素放在第一个位置。
- 如果需要扩容,则等扩容完毕再重复以上步骤。
- 删除
- 同查找过程,尝试找到 key 位置,如果找到,则清除对应该位置的数据。
- 扩容
- 插入和删除时都会进行扩容检查。
- 当装载因子(键数/桶数)达到 6.5 时,触发增量扩容,B加1哈希表长度翻倍。
- 6.5/8 约等于80%,是测试得到的较平衡的数值。
- 当溢出桶过多时,触发等量扩容,哈希表长度不变,溢出桶收缩,桶内元素重新排列,本质是碎片整理。
- 遍历
- map 的遍历是无序的,每次遍历都会设置随机起点,目的在于避免开发者利用顺序。
- 遍历过程中可以删除key,不会导致遍历失效。
- 遍历过程中虽然可以插入元素,但是新插入的元素是否会在后续的遍历中是不确定的。
闭包实现原理
- 当一个函数创建了另一个函数作为局部变量时,编译器就生成一个闭包。
- 闭包本身是个结构体,包含函数指针和局部变量的指针。
- 闭包会触发编译器的逃逸分析,以判断局部变量是否需要分配在堆上。
- 闭包是在堆中分配的,所以外部函数执行完成之后,闭包仍然存在。
defer 实现原理
- 编译器遇到 defer 语句,会生成一个_defer结构体(包含延迟执行的函数指针、参数返回值内存大小等)
- _defer结构体作为header,与参数返回值形成连续空间。
- 延迟函数的参数是预计算的,即参数在 defer 语句执行时就确定了。
- 所有_defer结构组成了一个链表,挂在协程上。
- _defer链表的插入使用头插法,在执行时从头到尾顺序执行,所以是LIFO。
- 有注册 defer 的函数,在 return 时,执行以下操作:
- 设置返回值。
- 执行 _defer 链中由当前函数注册的节点,执行过的节点摘除。
- 跳转回原函数继续执行。
panic 实现原理
- panic 本质是一个panic()特殊函数调用。
- panic 产生原理:
- 直接调用 panic() 函数,参数可以是任何类型的变量。
- 编译器产生,如除法运算时会增加对 0 值的判断,调用 panic()。
- 由系统进程的信号处理程序调用 panic(),如空指针或非法地址访问等。
- panic()函数实现原理:
- 产生一个结构体挂在协程上,包含是否恢复的标记。
- 执行 _defer链,执行过程中如果有调用了 recover(),则修改是否恢复的标记。
- _defer链执行完,如果标记恢复,则按正常返回逻辑。
- 如果标记不恢复,则打印panic信息,进程退出。
- recover() 实现原理:
- 修改是否恢复的标记。
- 返回 panic()时的参数。
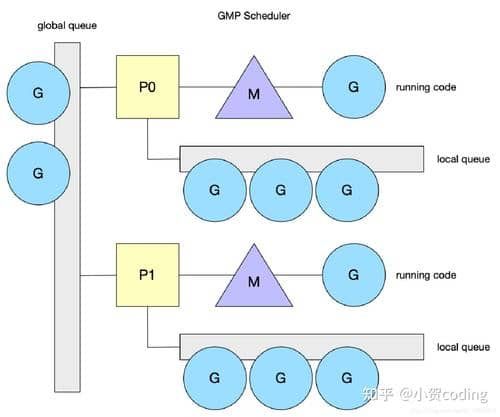
协程调度原理
协程的调度抽象看是一个生产者与消费者问题。程序生成协程G,线程M消费协程。
GM模型(早期版本(v1.1)的实现):
- 只有一个全局队列暂存 G,由多个 M 来获取 G 执行。
- 缺陷1:存在全局锁,多个M是并发从全局队列获取 G,所以需要对全局队列加锁,导致性能下降。
- 缺陷2:忽略了G的关系,比如G1创建了G2,G1和G2是大概率相关的,交给不同线程来执行会破坏时间和空间的局部性,导致性能下降。
GMP模型(后来版本的实现):
- P 的作用及特点:
- 将全局队列拆成多个本地队列,管理队列的结构是P。
- M 通过 P 队列获取 G 时不需要全局锁。
- 每个P的队列是固定长度256的数组,全局队列则是长度不限的链表。
- P中除了待运行队列外,还加了一个runnext的结构,为了优先运行刚创建的G,提高局部性。
- 线程缓存从 M 上转移到了 P,P 切换 M 时不需要重新分配线程缓存。
- 通过环境变量 GOMAXPROCS 控制 P 的数量。
- GOMAXPROCS 默认是 cpu 的核心数,使用容器时需要修改为限制的核心数。
- M 的消费逻辑:
- 先从绑定的 P 的本地队列(优先runnext)上获取 G。
- 然后从全局队列获取 P,另外每61次调度会检查一下全局队列,并且会将全局队列的 G 分给各个 P。
- 如果全局队列没有 G,则随机选择一个 p 偷一半 G 过来。
- 偷任务过程会访问并发访问本地队列,需要加自旋锁。
- M 的自旋状态表示绑定了 P正在获取 G。
- 如果还没有任务则休眠。
- G 的生产逻辑:
- 使用 go 关键字进行函数调用时,生成 G,优先放入 P 的 runnext 队列。
- runnext 满了,将 runnext的 G 踢出放入本地队列,再将 G 放入 runnext。
- 如果本地队列也满了,将本地队列的一半和 runnext踢出的 G 放入全局队列。
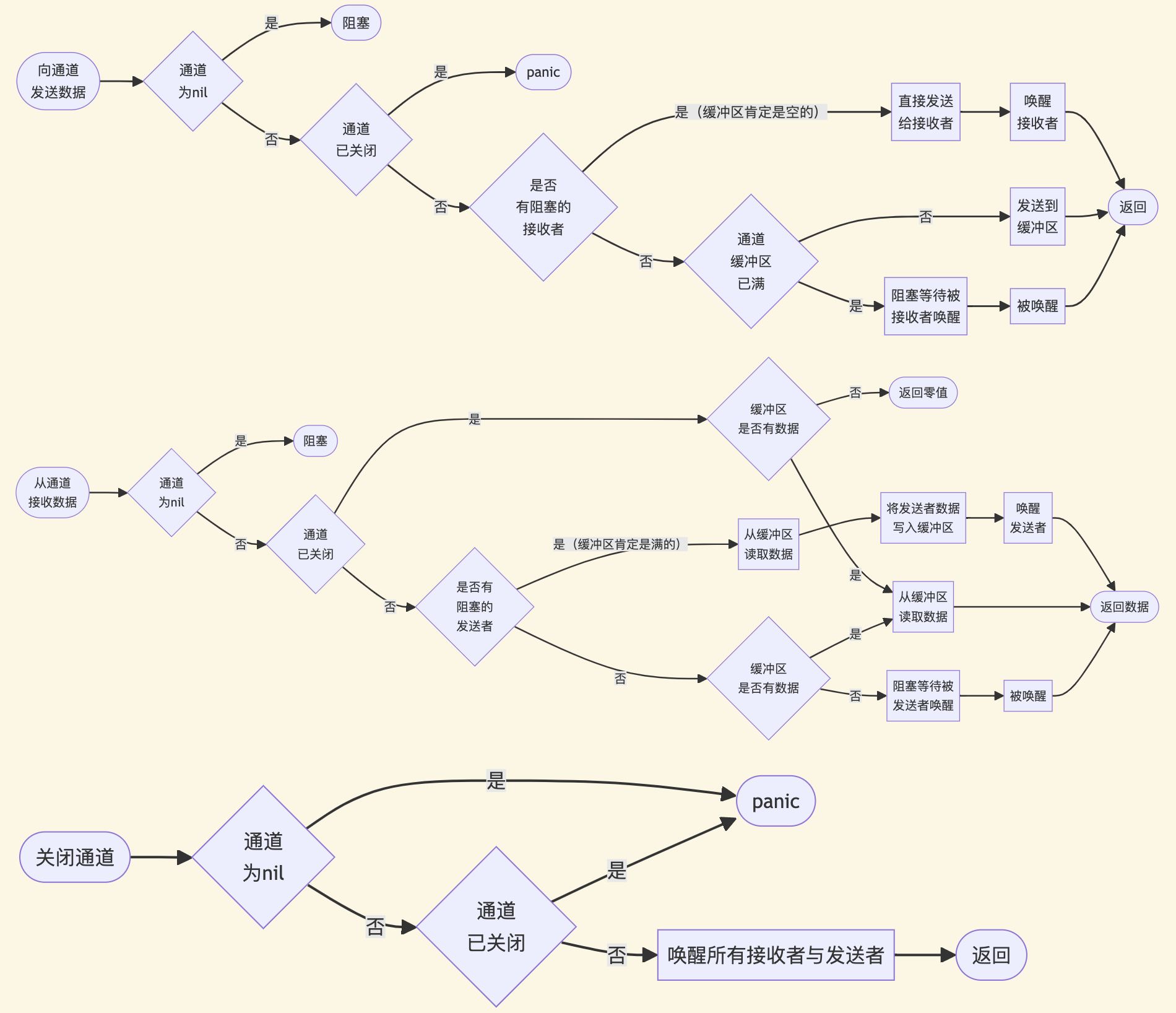
通道实现原理
- 通道创建时是在堆中创建了一个结构体,并返回指针,所以通道是引用类型。
- 通道结构体中主要包含:缓冲区循环数组,发送索引、接收索引、互斥锁、接收和发送的协程队列等。
- 读取缓冲区时,先加锁,再用结构体中的索引读写循环数组,索引位置循环自增,再释放锁。
- 当需要阻塞时,发送端或接收端会调用协程调度器,阻塞自己并让出系统线程。
- 当接收队列中存在阻塞协程时,缓冲区肯定是空的,发送端会直接复制数据到接收栈中,不会经过缓冲区也不需要加锁。
- 当发送队列中存在阻塞协程时,缓冲区肯定是满的,接收端需要从缓冲区读取数据,再将发送者数据写入缓冲区,然后才唤醒发送者。
通道的操作流程图(有缓冲区情况):
内存分配
栈
- 栈是专属于协程的内存空间,用于存储局部变量、函数参数、返回值等。
- 栈内存分配的单位是栈帧。
- 栈帧大小在编译期确定,由编译器分配和释放。
- 在函数调用开始时push栈帧,函数调用结束时pop栈帧。
- 函数参数和返回值在调用者的栈帧中。
- 栈的大小会随着函数调用层次增加而增加。
- 协程栈的初始容量是 2K,可以动态增长到 1G。
堆
- 堆是协程间共享的内存空间。
- 分配在堆上的数据:
- 全局变量。
- 发生逃逸的值类型数据。
- 未被优化到栈上的引用类型数据(slice 可能被优化到栈上)。
- 堆内存管理基于 TCMalloc 的核心思想构建:
- 为每个线程分配一块缓存,小内存从缓存直接分配避免系统调用,且避免加锁。
- 提供所有线程共享的中心缓存,与线程缓存结构相同。
- 分配的单位是内存分页(1分页为8K)的整数倍。
- 缓存的结构按空间大小(分页数量)提前划分好,方便直接提取使用。
- 在中心缓存与系统内存之间增加一层堆内存,作为系统内存的抽象。
- 小对象、中对象、大对象的分配策略差异化处理,平衡内存利用率和分配效率。
- 与 TCMalloc 的差异:
- 线程缓存是挂在 GMP 模型的 P 下。
- 线程缓存提供的是可能小于内存分页的对象。
逃逸分析
- 逃逸分析是指在编译期分析代码,决定是在栈还是堆上分配内存。
- 如果局部变量的作用域超出了函数范围,则会逃逸到堆上。
- 如果局部变量体积过大,也会逃逸到堆上。
- new() 或 make()出来的局部变量,如果没超出函数范围,也可能被优化到栈上。
- 指针和闭包都会引发逃逸分析。
- 使用命令输出分析结果:go build -gcflags '-m -l' x.go
垃圾回收
- 堆分配的内存是由垃圾回收进行自动释放的。
- Go 垃圾回收的特点:
- 渐进式回收,将代价分散到整个程序运行期间,避免停顿。
- 并发式回收,垃圾回收与程序运行并发执行。
- Go 垃圾回收的实现基于三色标记法+混合写屏障法。
- 三色标记法:
- 从根出发,可达的对象全部标记为灰色。
- 遍历所有灰色,已遍历标记黑色,对灰色引用的白色对象标记灰色。
- 重复遍历灰色,直至不存在灰色对象。
- 最后回收白色对象。
- 三色标记法可以处理循环引用问题,并且可以并行处理不同区域的对象。
- 根是全局变量和协程栈变量等。
- 混合写屏障:
- 标记过程中,并发写入可能导致标记错误,引发野指针或内存泄露。
- 编译期写操作插入hook,确保三色不变性。
- 三色不变性,满足其中之一则可:
- 强三色不变性,黑色不能引用白色。
- 弱三色不变性,黑色引用的白色必须有灰色的引用作为保护。
- 垃圾回收的触发:
- 主动触发 runtime.GC()。
- 定期触发,默认每 2 分钟,守护协程触发。
- 内存分配量超过阈值时触发。
标准库
fmt
提供格式化输入与输出操作。
格式化输出
打印到控制台:
- func Print(a ...interface{}) (n int, err error)
- 打印任何数据。
- func Println(a ...interface{}) (n int, err error)
- 打印任何数据并且换行。
- func Printf(format string, a ...interface{}) (n int, err error)
- 格式化打印任何数据。
- %v 任意值
- %+v 任意值,如果是struct则带字段
- %#v 任意值,用 Go 的语法表示
- %T 打印值的类型
- %t 布尔值
- %s 字符串
- %d 整数,十进制
- %x 整数,十六进制,使用a-f
- %X 整数,十六进制,使用A-F
- %o 整数,八进制
- %b 整数,二进制
- %f 浮点数,默认宽度,默认精度
- %.2f 浮点数,默认宽度,精度 2,四舍五入
- %9.2f 浮点数,宽度9(不够补空格),精度 2
生成字符串:
- func Sprint(a ...interface{}) string
- func Sprintln(a ...interface{}) string
- func Sprintf(format string, a ...interface{}) string
输出到 io:
- func Fprint(w io.Writer, a ...interface{}) (n int, err error)
- func Fprintf(w io.Writer, format string, a ...interface{}) (n int, err error)
- func Fprintln(w io.Writer, a ...interface{}) (n int, err error)
生成 error:
- func Errorf(format string, a ...interface{}) error
x := struct {
name string
age int
}{"john", 10}
fmt.Printf("%v\n", x) //{john 10}
fmt.Printf("%+v\n", x) //{name:john age:10}
fmt.Printf("%#v\n", x) //struct { name string; age int }{name:"john", age:10}
fmt.Printf("%9.2f\n", 123.456) // 123.46,前面有3个空格整体宽度9字符
格式化输入
控制台输入:
- func Scan(a ...interface{}) (n int, err error)
- 用空白符(空格、制表、换行)作为分隔符依次输入到参数,传指针。
- 空白符可以多个。
- 输入完成或出错才返回,返回成功个数和失败原因。
- func Scanln(a ...interface{}) (n int, err error)
- 用空白符(空格、制表)作为分隔符依次输入到参数,遇到换行结束输入。
- func Scanf(format string, a ...interface{}) (n int, err error)
- 格式化输入,必须按照 format 要求的格式输入,否则报错。
字符串输入:
- func Sscan(str string, a ...interface{}) (n int, err error)
- func Sscanln(str string, a ...interface{}) (n int, err error)
- func Sscanf(str string, format string, a ...interface{}) (n int, err error)
io 输入:
- func Fscan(r io.Reader, a ...interface{}) (n int, err error)
- func Fscanln(r io.Reader, a ...interface{}) (n int, err error)
- func Fscanf(r io.Reader, format string, a ...interface{}) (n int, err error)
strings
提供字符串相关操作,包括大小写转换、修剪、查找替换、拆分拼接等。
字符串处理函数
- 大小写
- func EqualFold(s, t string) bool
- 不区分大小写比较字符串
- 如果是区分大小写,使用运算符==
- func ToLower(s string) string
- func ToUpper(s string) string
- 修剪
- func Trim(s, cutset string) string
- func TrimLeft(s, cutset string) string
- func TrimRight(s, cutset string) string
- func TrimSpace(s string) string
- func TrimPrefix(s, prefix string) string
- func TrimSuffix(s, suffix string) string
- func TrimFunc(s string, f func(rune) bool) string
- 查找
- func Contains(s, substr string) bool
- func HasPrefix(s, prefix string) bool
- func HasSuffix(s, suffix string) bool
- func Index(s, substr string) int
- 替换
- func Replace(s, old, new string, n int) string
- func ReplaceAll(s, old, new string) string
- 拆分与拼接
- func Split(s, sep string) []string
- func Join(elems []string, sep string) string
strings.Builder
- 用于高效处理字符串拼接,如果是少量拼接用运算符+。
- func (b *Builder) WriteString(s string) (int, error)
- 写入字符串,返回长度,error 为 nil
- func (b *Builder) String() string
- 返回字符串
var sb strings.Builder
sb.WriteString("Hello")
sb.WriteString("World")
fmt.Println(sb.String()) //HelloWorld
strconv
提供字符串转换相关操作。
s := strconv.Itoa(123) //int 转字符串,十进制
fmt.Println(s)
i, err := strconv.Atoi("123") //字符串转 int,十进制
fmt.Println(i, err)
i64, err := strconv.ParseInt("666", 8, 64) //字符串转 int,8 进制
strBit := strconv.FormatInt(i64, 2) //int 转字符串,2 进制
fmt.Println(strBit, err) //八进制 666 对应二进制 110110110
b, err := strconv.ParseBool("TRUE") //1 t T TRUE true True都为真,0 f F FALSE false False为假
fmt.Println(b, err) //true
f, err := strconv.ParseFloat("123.4567", 64) //字符串转 float64
fmt.Println(f, err)
time
提供时间相关操作,包括取系统时间与时区、格式化转换、比较、定时器、协程睡眠等。
//获取当前时间
now := time.Now()
fmt.Println("1: ", now)
//转字符串 24小时制
strNow := now.Format("2006-01-02 15:04:05")
fmt.Println("2: ", strNow)
fmt.Println("3: ", now.Format("2006-01-02 03:04:05 PM")) //12小时制
//字符串转日期,使用 0 时区
utcTime, err := time.Parse("2006-01-02 15:04:05", "2023-01-02 14:00:00")
fmt.Println("4: ", utcTime, err)
//字符串转日期,使用系统的本地时区
localTime, err := time.ParseInLocation("2006-01-02 15:04:05", "2023-01-02 14:00:00", time.Local)
fmt.Println("5: ", localTime, err)
//获取年月日时分秒
fmt.Println("6: ", now.Year(), now.Month(), now.Day(), now.Hour(), now.Minute(), now.Second())
//获取unix时间戳(UTC1970起秒数)
fmt.Println("7: ", now.Unix())
//比较是否相等,会考虑时区影响
fmt.Println("8: ", now.Equal(now.UTC()))
//日期加减
fmt.Println("9: ", now.AddDate(-1, 2, 3)) //年-1,月+2,日+3
//时间加减
fmt.Println("10:", now.Add(time.Hour*2-time.Minute*2)) //时+2,分-2
//比较时间大小
fmt.Println("11:", now.Before(now.AddDate(0, 0, 1)))
fmt.Println("12:", now.After(now.AddDate(0, 0, -1)))
//时间差,获取时间间隔
duration := now.Sub(now.AddDate(0, 0, -1))
fmt.Println("13:", duration, duration.Hours(), duration.Minutes(), duration.Seconds())
//time.Since() 等于 time.Now().Sub()
fmt.Println("14:", time.Since(now.AddDate(0, 0, -2)))
//定时器,执行一次
time.AfterFunc(2*time.Second, func() {
fmt.Println("15: ", time.Since(now))
})
//定时器,间隔触发
ticker := time.NewTicker(3 * time.Second)
go func() {
for x := range ticker.C {
fmt.Println("16: ", x.Sub(now))
}
}()
//协程睡眠
time.Sleep(time.Second * 10)
ticker.Stop()
/*输出结果
1: 2023-09-14 13:20:17.650942692 +0800 CST m=+0.000047084
2: 2023-09-14 13:20:17
3: 2023-09-14 01:20:17 PM
4: 2023-01-02 14:00:00 +0000 UTC <nil>
5: 2023-01-02 14:00:00 +0800 CST <nil>
6: 2023 September 14 13 20 17
7: 1694668817
8: true
9: 2022-11-17 13:20:17.650942692 +0800 CST
10: 2023-09-14 15:18:17.650942692 +0800 CST m=+7080.000047084
11: true
12: true
13: 24h0m0s 24 1440 86400
14: 48h0m1.640158075s
15: 3.640260837s
16: 4.640267816s
16: 7.642234665s
16: 10.642233452s
*/
math
提供数学相关操作,包括各种数字类型的最大值常量、取整、取随机数、数学函数等。
- 常量 MaxInt/MaxInt8/MaxUint/MaxFloat32/MaxFloat64/Pi等
- 向上取整 func Ceil(x float64) float64
- 向下取整 func Floor(x float64) float64
- 四舍五入取整 func Round(x float64) float64
- 取绝对值 func Abs(x float64) float64
- 取最大 func Max(x, y float64) float64
- 取最小 func Min(x, y float64) float64
- 取随机整数 func Intn(n int) int
- 取随机浮点数,范围[0, 1.0) Float64() 和 Float32()
- 其他常用函数,如三角函数、对数指数等
sort
提供排序相关操作,支持基本类型或自定义类型的排序。 内部实现了插入排序、归并排序、堆排序和快速排序,会根据数据量和是否稳定排序自动选择算法,确保效率。
基本类型排序
标准库定义了以下类型,并实现了排序接口:
- type IntSlice []int
- type Float64Slice []float64
- type StringSlice []string
//int切片正序
arrInt := []int{5, 3, 7, 1, 9}
sort.Ints(arrInt)
fmt.Println(arrInt)//[1 3 5 7 9]
//int切片逆序
sort.Sort(sort.Reverse(sort.IntSlice(arrInt)))
fmt.Println(arrInt)//[9 7 5 3 1]
//float切片正序
arrFloat := []float64{2.0, 9.3, 2.3, 1.1, 6.3}
sort.Float64s(arrFloat)
fmt.Println(arrFloat)//[1.1 2 2.3 6.3 9.3]
//float切片逆序
sort.Sort(sort.Reverse(sort.Float64Slice(arrFloat)))
fmt.Println(arrFloat)//9.3 6.3 2.3 2 1.1]
//string切片正序
arrStr := []string{"x3", "x1", "v", "z", "b", "a"}
sort.Strings(arrStr)
fmt.Println(arrStr)//[a b v x1 x3 z]
//string切片逆序
sort.Sort(sort.Reverse(sort.StringSlice(arrStr)))
fmt.Println(arrStr)//[z x3 x1 v b a]
自定义类型排序
type Person struct {
Name string
Age int
}
type PersonSlice []Person
func (s PersonSlice) Len() int { return len(s) }
func (s PersonSlice) Less(i, j int) bool { return s[i].Age < s[j].Age }
func (s PersonSlice) Swap(i, j int) { s[i], s[j] = s[j], s[i] }
func main() {
persons := PersonSlice{{"a", 20}, {"b", 5}, {"c", 10}, {"d", 5}}
//对实现了 sort.Interface 接口的类型排序
sort.Sort(persons)
//稳定排序
sort.Stable(persons)
fmt.Println(persons) //[{b 5} {d 5} {c 10} {a 20}]
//二分查找,返回最小符合条件的元素索引,注意后面元素必须全部符合条件
x := sort.Search(len(persons), func(i int) bool {
return persons[i].Age >= 10
})
fmt.Println(persons[x:]) //[{c 10} {a 20}]
//直接传入 Less 函数排序,无需实现 sort.Interface 接口
sort.Slice(persons, func(i, j int) bool {
return persons[i].Name < persons[j].Name
})
fmt.Println(persons) //[{a 20} {b 5} {c 10} {d 5}]
}
os
提供操作系统相关操作,包括文件、目录、进程、环境变量等操作。
//写入文件,0666为Unix权限代码,八进制0666等于二进制110110110,表示三种身份都是读写
if err := os.WriteFile("a.txt", []byte("hello world"), 0b110110110); err != nil {
fmt.Println(err)
}
//读取文件
buf, err := os.ReadFile("a.txt")
if err != nil {
fmt.Println(err)
}
fmt.Println(string(buf))
//删除文件
if err := os.Remove("a.txt"); err != nil {
fmt.Println(err)
}
//创建多级目录
if err := os.MkdirAll("b/c", 0666); err != nil {
fmt.Println(err)
}
//删除目录
if err := os.RemoveAll("b"); err != nil {
fmt.Println(err)
}
//获取临时目录
tmpDir := os.TempDir()
fmt.Println(tmpDir)
//获取工作目录
dir, err := os.Getwd()
if err != nil {
fmt.Println(err)
} else {
fmt.Println(dir)
}
//获取环境变量
x := os.Getenv("GOPATH")
fmt.Println(x)
//进程退出,0 为正常,非 0 为出错
os.Exit(0)
sync
提供处理同步的工具,包括互斥锁、读写锁等。
WaitGroup
组等待,用于实现主协程等待指定数量的子协程执行完成后再继续执行。
func main() {
wg := sync.WaitGroup{}
for i := 0; i < 10; i++ {
wg.Add(1)
go func(i int) {
defer wg.Done()
fmt.Print(i, " ")
}(i)
}
wg.Wait()
}
互斥锁
互斥锁(sync.Mutex)用于保证在任意时刻,只有一个协程访问某个数据。
type Counter struct { //支持加锁的计数器
sync.Mutex//嵌套,使Counter支持Mutex的方法
Data int
}
func main() {
counter := Counter{}
wg := sync.WaitGroup{} //用于辅助主协程等待
for i := 0; i < 1000; i++ {
wg.Add(1)
go func() {
defer wg.Done()
counter.Lock() //加锁确保不会并发修改
defer counter.Unlock() //延迟解锁
counter.Data++
}()
}
wg.Wait()
fmt.Println(counter.Data)
//如果没有发生并发修改,将输出1000,否则小于1000
}
读写锁
读写锁(sync.RWMutex)可以被同时多个读取者持有或唯一个写入者持有。
func main() {
m := sync.RWMutex{}
wg := sync.WaitGroup{}
start := time.Now()
for i := 0; i < 3; i++ {
wg.Add(1)
go func(i int) {
defer wg.Done()
m.Lock()
fmt.Println(int(time.Since(start).Seconds()), "write begin ", i)
defer m.Unlock()
time.Sleep(time.Second * 5)
fmt.Println(int(time.Since(start).Seconds()), "write end ", i)
}(i)
}
time.Sleep(time.Second * 1)
for i := 0; i < 3; i++ {
wg.Add(1)
go func(i int) {
defer wg.Done()
m.RLock()
fmt.Println(int(time.Since(start).Seconds()), "read begin ", i)
defer m.RUnlock()
time.Sleep(time.Second * 1)
fmt.Println(int(time.Since(start).Seconds()), "read end ", i)
}(i)
}
wg.Wait()
}
/*输出结果可见:写独占读并发
0 write begin 2
5 write end 2
5 read begin 2
5 read begin 0
5 read begin 1
6 read end 1
6 read end 2
6 read end 0
6 write begin 0
11 write end 0
11 write begin 1
16 write end 1
*/
sync.Map
Go 的内建类型map支持并发读,但不支持并发写。有两种方法来实现 map 并发读写:
- 用 map 结合 RWMutex
- go 1.9 之后用标准库 sync.Map
- 区别是后者以空间换时间,内部采用读写分离两个 map,读时不需要加锁。
m := sync.Map{}
for i, c := range "abcdefg" {
m.Store(string(c), i) //写入
}
v1, ok := m.Load("c") //读取
fmt.Println(v1, ok) //2 true
m.Delete("c") //删除
v2, ok := m.Load("c") //再次读取,不存在
fmt.Println(v2, ok) //<nil> false
//遍历
m.Range(func(key, value interface{}) bool {
fmt.Println(key, value)
return true //返回 false 终止循环
})
net
net包及其子包 net/http、net/url 包等提供了HTTP、TCP、UDP 等网络协议和相关辅助功能的实现。
HTTP协议
http 服务端的实现主要包括以下类型:
- http.Server:服务端核心结构,用于管理和监听请求。
- http.ServeMux:多路复用器结构,用于分发请求。
- http.ResponseWriter:响应输出接口,用于写入响应内容。
- http.Request:请求结构,用于读取请求内容。
func httpServer() {
mux := http.NewServeMux()
mux.HandleFunc("/get", func(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("resp of get " + r.URL.Query().Get("param")))
})
mux.HandleFunc("/postform", func(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("resp of postform " + r.PostFormValue("param")))
})
mux.HandleFunc("/postjson", func(w http.ResponseWriter, r *http.Request) {
reqBody, err := io.ReadAll(r.Body)
if err != nil {
fmt.Println(err)
return
}
w.Write([]byte("resp of postjson " + string(reqBody)))
})
server := &http.Server{
Addr: ":8080",
Handler: mux,
ReadTimeout: 10 * time.Second,
WriteTimeout: 10 * time.Second,
}
err := server.ListenAndServe()
if err != nil {
fmt.Println(err)
}
}
func main() {
go httpServer()
time.Sleep(time.Second * 1) //简单等待服务端启动
processResult := func(resp *http.Response, err error) {
if err != nil {
fmt.Println(err)
return
}
defer resp.Body.Close()
buf, err := io.ReadAll(resp.Body)
if err != nil {
fmt.Println(err)
return
}
fmt.Println(string(buf))
}
//http get
processResult(http.Get("http://127.0.0.1:8080/get?param=123"))
//http post form
processResult(http.PostForm("http://127.0.0.1:8080/postform", url.Values{"param": {"456"}}))
//http post json
processResult(http.Post("http://127.0.0.1:8080/postjson", "application/json", bytes.NewReader([]byte(`{"param":"789"}`))))
}
TCP协议
func processError(err error) { //用于简单处理错误
if err != nil {
fmt.Println(err)
os.Exit(1)
}
}
func tcpServer() {
listener, err := net.Listen("tcp", "127.0.0.1:8080") //监听
processError(err)
for {
conn, err := listener.Accept() //建立连接
processError(err)
go func() {
defer conn.Close() //延迟关闭连接
//先读取数据,约定换行作为边界符
data, err := bufio.NewReader(conn).ReadString('\n')
processError(err)
fmt.Print("server read:", data)
//再写入数据,data已包含换行
_, err = conn.Write([]byte("resp " + data))
processError(err)
}()
}
}
func tcpClient() {
conn, err := net.Dial("tcp", "127.0.0.1:8080") //建立连接
processError(err)
defer conn.Close() //延迟关闭连接
//先写入数据,约定换行作为边界符
_, err = conn.Write([]byte("hello world\n"))
processError(err)
//再读取数据,约定换行作为边界符
data, err := bufio.NewReader(conn).ReadString('\n')
processError(err)
fmt.Print("client read:", data)
}
func main() {
go tcpServer()
time.Sleep(time.Second) //简单等待服务端启动
tcpClient()
}
UDP协议
func processError(err error) { //用于简单处理错误
if err != nil {
fmt.Println(err)
os.Exit(1)
}
}
func udpServer() {
udp, err := net.ListenUDP("udp", &net.UDPAddr{ //开始监听
IP: net.IPv4(0, 0, 0, 0),
Port: 8080,
})
processError(err)
defer udp.Close() //延迟关闭监听
for {
//读取数据
buf := [512]byte{}
n, addr, err := udp.ReadFromUDP(buf[:])
processError(err)
data := string(buf[0:n])
fmt.Println("server read:", data, "from:", addr.String())
//再写入数据
_, err = udp.WriteToUDP([]byte("resp "+data), addr)
processError(err)
}
}
func udpClient() {
udp, err := net.DialUDP("udp", nil, &net.UDPAddr{
IP: net.IPv4(0, 0, 0, 0),
Port: 8080,
})
processError(err)
defer udp.Close() //延迟关闭
//先写入数据
_, err = udp.Write([]byte("hello world"))
processError(err)
//再读取数据
buf := [512]byte{}
n, addr, err := udp.ReadFromUDP(buf[:])
processError(err)
data := string(buf[0:n])
fmt.Println("client read:", data, "from:", addr.String())
}
func main() {
go udpServer()
time.Sleep(time.Second) //简单等待服务端启动
udpClient()
}
context
context包:提供上下文相关功能,通常只适用于后端接口实现请求上下文的应用场景。
上下文:表示执行某个任务时所处的环境和背景状态。
区分请求参数和请求上下文信息:
- 请求参数:只适用于某个请求的参数信息。
- 请求上下文信息:适用于所有请求的信息,如认证信息、链路追踪ID、超时时间等。
使用方法:
- 在最顶层的协程(如 main函数)中用 context.Background() 创建一个根上下文。
- 上游通过函数参数的方式传递上下文给下游,可以跨协程传递,上下文操作是并发安全的。
- 上游使用 context.WithCancel(ctx) 创建一个可取消的子上下文,返回值包括取消函数。
- 上游使用 context.WithCancelCause(ctx) ,则取消函数包括取消原因。
- 上游使用 context.WithDeadline(ctx, deadlineTime) 创建一个带截止时间的子上下文。
- 上游使用 context.WithTimeout(ctx, duration) 创建一个带截止时间的子上下文。
- 上游使用 context.WithValue(ctx, key, value) 创建一个带某个KV的子上下文。
- 层级创建的所有上下文形成了一棵树,某个节点被取消或到达截止时间,其所有子孙上下文都会取消,父及兄弟节点则不受影响。
- 下游通过 ctx.Done()方法获取取消信号,返回的是只读通道,取消时通道被关闭。
- 下游通过 ctx.Deadline()方法获取截止时间。
- 下游通过 ctx.Value(key) 获取某个KV的值,只会向所有祖先节点查找,不会向子孙节点查找。
- 下游通过 ctx.Err() 获取错误信息,获取取消原因通过 context.Cause(ctx)。
使用建议:
- 将上下文作为函数的第一参数,不要放到结构体中。
- 不要传递 nil 作为上下文,使用 context.TODO()。
- 不要使用上下文传递请求参数,不要滥用上下文的 KV 信息。
- WithValue()的 Key 可以用空struct自定义类型,即避免内存开销又能避免冲突。
底层原理:
- context.Background()和context.TODO() 返回的是内部的emptyCtx,空上下文。
- WithCancel() 内部将父上下文包装成cancelCtx,启动守护协程确保父取消信号的传递,另外返回一个用于终止本cancelCtx的闭包函数。
- WithDeadline()和WithTimeout() 内部将父上下文包装成timerCtx,是在 cancelCtx 基础上增加了定时器,定时器超时则触发取消信号。
- WithValue() 内部将父上下文包装成valueCtx,只增加了一个 KV 信息。
- 下游调用 ctx.Value(key)时,如果与当前 ctx 的 key 不等则查找父上下文,直到根节点。
type userNameKey struct{} //定义空struct做key的类型
func process(ctx context.Context) {
now := time.Now()
for { //每秒检测一次取消信号
select {
case <-ctx.Done(): //上游取消或到达截止时间时,返回已关闭通道
fmt.Println("process done, err:", ctx.Err())
return
default: //有 default 分支的 select 不会阻塞
time.Sleep(time.Second * 1)
userName := ctx.Value(userNameKey{}) //获取上下文信息
fmt.Println(int(time.Since(now).Seconds()), userName)
}
}
}
func main() {
//创建一个超时时间为10秒的可取消上下文
ctx, cancel := context.WithTimeout(context.Background(), time.Second*10)
//创建一个带键值对的子上下文
ctx = context.WithValue(ctx, userNameKey{}, "wills")
go process(ctx) //将上下文传递给下游
time.Sleep(time.Second * 5) //等待执行 5 秒后取消
cancel() //WithTimeout()返回的闭包函数,上游取消时调用
time.Sleep(time.Second * 5) //简单等待子线程退出后再退出
}
reflect
reflect 包提供反射相关功能,反射是指程序在运行期对自己进行检测、修改和扩展的能力。 通过反射,可以获取类型、字段、方法等反射信息,可以修改字段值,支持数组、切片、map、指针、接口等复杂类型。使程序在运行期获得极为灵活的能力。 常用方法或接口:
- reflect.TypeOf()获取任意对象的类型反射信息 reflect.Type。
- reflect.ValueOf()获取任意对象的值反射信息 reflect.Value。
- reflect.Type 代表任意对象的类型反射信息,包括:
- Kind() 所属的原生数据类型,枚举值,如Int/String/Array/Slice/Struct/Interface/Func/UnsafePointer等。
- NumField() 字段数量,常用于遍历字段。
- Field() 获取字段反射信息 reflect.StructField。
- FieldByName() 根据字段名获取字段反射信息 reflect.StructField。
- reflect.StructField 代表一个结构体字段的反射信息,包括:
- Name 字段名。
- Type 字段类型的反射信息 reflect.Type。
- Tag 字段标签反射信息 reflect.StructTag。
- reflect.Value 代表任意对象的值反射信息,包括:
- CanSet() 是否可设置,如首字母小写的字段是不可设置的。
- CanAddr() 是否可获取地址,CanSet的一定CanAddr,反之则不然。
- Interface() 返回字段值,以 Interface{}的形式。
- Set() 设置字段值。
- Len() 返回数组、切片、字符串等类型值的长度。
- Index() 返回数组、切片、字符串等类型值的元素值反射信息。
type A struct {
Astr1 string `ignore:"true"`
Astr2 string
AsliceB []B
innerStr1 string //内部字段
}
type B struct {
Bstr1 string
Bstr2 string `ignore:"true"`
}
// 传入任何类型数据,清空其类型为 string 的公开字段值,如果字段标记 ignore 则忽略。
// 支持嵌套struct和切片类型。
func ClearAllStringFields(obj any) error {
objType, objValue := reflect.TypeOf(obj), reflect.ValueOf(obj)
if objType.Kind() == reflect.Slice { //slice需要循环递归处理
lstLen := objValue.Len()
for j := 0; j < lstLen; j++ {
objItem := objValue.Index(j)
if objItem.Kind() == reflect.Ptr {
ClearAllStringFields(objItem.Interface())
continue
}
if objItem.CanAddr() {
ClearAllStringFields(objItem.Addr().Interface())
}
}
return nil
}
if objType.Kind() == reflect.Ptr { //指针需要取值
objType, objValue = objType.Elem(), objValue.Elem()
}
if objType.Kind() != reflect.Struct {
return nil
}
fieldNum := objType.NumField()
for i := 0; i < fieldNum; i++ { //遍历结构体的字段
curField := objType.Field(i)
curValue := objValue.Field(i)
if !curValue.CanSet() { //过滤掉不可修改的字段,首字母小写的字段不可修改
continue
}
if curField.Type.Kind() == reflect.Struct ||
curField.Type.Kind() == reflect.Slice {
ClearAllStringFields(curValue.Interface())
continue
}
ignore := curField.Tag.Get("ignore")
if ignore == "true" {
continue
}
curValue.Set(reflect.Zero(curValue.Type()))
}
return nil
}
func main() {
s := []A{
{"no", "yes", []B{{Bstr1: "yes", Bstr2: "no"}, {Bstr1: "yes", Bstr2: "no"}}, "no"},
{"no", "yes", []B{{Bstr1: "yes", Bstr2: "no"}, {Bstr1: "yes", Bstr2: "no"}}, "no"},
}
fmt.Printf("before clear:\n%+v\n", s)
ClearAllStringFields(s)
fmt.Printf("after clear:\n%+v\n", s)
}
应用框架
web 框架
gin
Gin 是轻量级的 Web 框架,用于快速搭建 RESTful 风格的 Web 服务。 有以下特点:
- 路由,既简单又丰富的路由解析功能。
- 速度,业界测试 Gin 路由的性能极好。
- 中间件,实现请求或响应拦截器。
- 内置渲染,支持JSON/XML/HTML等格式进行响应渲染。 原理:
- 路由的解析采用基数树(压缩字典树)数据结构。
func MyMiddleware1() gin.HandlerFunc { //中间件 1
return func(context *gin.Context) {
fmt.Println("MyMiddleware1 begin")
context.Next() //执行下一个中间件后再继续
fmt.Println("MyMiddleware1 end")
}
}
func MyMiddleware2() gin.HandlerFunc { //中间件 2
return func(context *gin.Context) {
fmt.Println("MyMiddleware2")
}
}
func main() {
r := gin.Default() //默认引擎注册了日志中间件和panic处理中间件
r.Use(MyMiddleware1(), MyMiddleware2()) //注册两个自定义中间件
r.GET("/hello", func(c *gin.Context) { //注册GET路由
c.JSON(http.StatusOK, gin.H{
"message": "Hello world",
})
})
r.GET("/hello/:id", func(c *gin.Context) { //注册GET路由,支持URL参数
id := c.Param("id")
c.JSON(http.StatusOK, gin.H{
"message": "Hello " + id,
})
})
r.Run(":8080")
}
/* test.http
###
GET http://127.0.0.1:8080/hello HTTP/1.1
###
GET http://127.0.0.1:8080/hello/123 HTTP/1.1
*/
其他
Beego是一个全功能的Web开发框架,采用MVC架构,相对缺点是性能弱,代码结构复杂。 iris功能比gin丰富,支持MVC,基础功能与gin比较接近,比Beego新,比Beego性能好。
orm 框架
orm 框架有 gorm 和 xorm 等,其中社区活跃度是 gorm。
rpc 框架
net/rpc
net/rpc 是标准库自带rpc框架。使用标准库 encoding/gob 进行编解码,无法跨语言调用。
gRPC
gRPC 是谷歌开发的rpc框架,有以下特点:
- 高性能,基于 HTTP/2协议,利用多路复用、头部压缩等特性,可以实现低延迟高吞吐量。
- 支持 IDL,使用 protobuf 作为接口定义语言。
- 支持跨语言,支持多种语言。
- 支持双向流式RPC。