- 进程vs线程
俗话说进程是分配资源的基本单位, 线程 是调度执行的基本单位。可是,从 linux内核 的视角看,进程和线程都是task_ struct 而已。
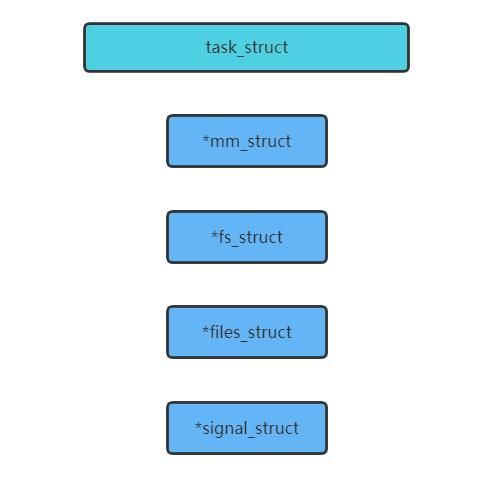
task_struct是个很大的结构,重点有pid、mm(进程使用的内存)、fs(文件系统,比如chroot、CWD)、files、signal。调度,就是在调度task_struct。
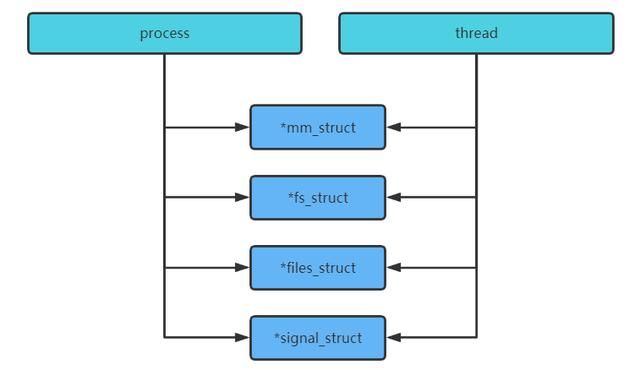
所谓线程(通过调用 pthread _create->clone),只是共享了进程的mm、fs、files、signal而已,如下图所示:
当进程有多个线程时,task_struct里面的pid就是真实的pid,使用top -H的时候可以看到这个pid。而top命令的时候,只能看到进程pid,也就是所谓的TGid,这是linux对用户的欺骗性。
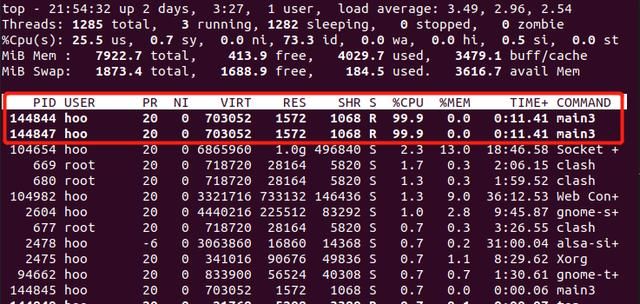
上图是top -H的结果
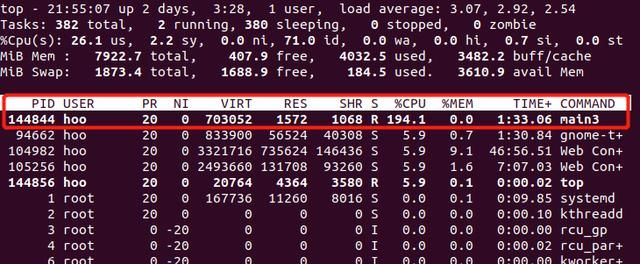
上图为top的结果
- 进程的6种状态
进程是一种资源,不会无限扩大,cat /proc/sys/kernel/pid_max可以显示最大的pid。进程有6种状态:就绪状态ready、运行态running、睡眠态sleep(可进一步分为浅睡眠态、深睡眠态)、僵尸态、停止态。
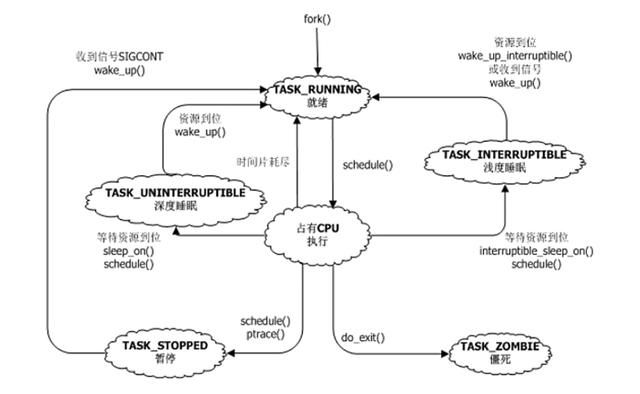
linx的进程是 fork 出来的(init 1号进程是0进程fork的,0进程是内核本来就有不用fork产生),这时就是就绪态。调度到CPU上执行就是运行态。因为是分时调度,时间片用完了或者被抢占了就又可以回到就绪态。有时候会等资源,所以有睡眠态。这是3个基本态。
进程死掉,不是直接消失,而是资源清理掉以后(不存在 内存泄漏 )剩下个躯壳task_struct,这就是僵尸。当父进程执行wait4系统调用后才真正消失。父进程wait之前的状态就是僵尸态。僵尸态的作用是父进程可以通过task_struct的exit_code了解进程的死因。在僵尸态用kill -9也没用,因为僵尸杀死还是个僵尸而已。
linux中进程从来都是白发人送黑发人。如果子进程没死父进程先死了就托孤。先向上找subreaper(进程可以把自己声明为subreaper),找到就托孤,找不到就托给init,init是个总reaper, reaper 就是死神。不会存在孤儿。是个特别和谐的世界。
再看停止态。停止态实际上是被动暂停。比如按下ctl+z。cpulimit这个程序实际上就是不停地通过暂停恢复进程来达到控制进程cpu使用率的目的。
cpulimit -l -p 143360
比如上面的命令是控制143360这个进程的 cpu 占用率为10%左右,因为cpulimit控制不是很精确。
再看睡眠态。浅睡眠和 深睡眠 都是等待资源进程自己去睡觉了。不同的是浅睡眠除了可以被资源到位后唤醒之外,还可以被信号唤醒,而深睡眠只能被资源唤醒。所以对深睡眠进程执行kill -9也没用。深睡眠是为了避免浅睡眠被唤醒后资源仍未准备好又去睡眠反反复复的情况。
0进程是优先级最低的进程,如果其他进程都睡眠,0进程才运行,0进程一运行就把CPU置成低功耗。
- COW(copy on write)机制
linux的fork会产生一个经典的现象——copy on write。
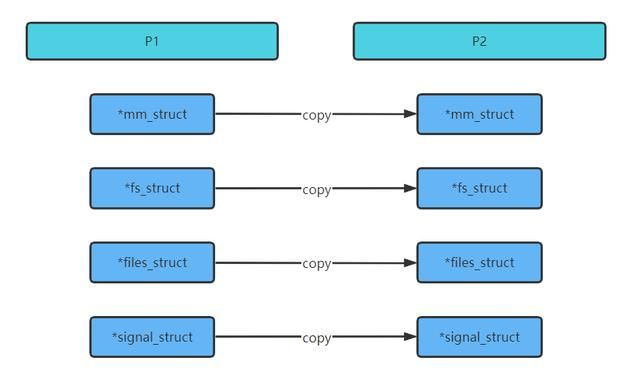
如图,P2是P1 fork出来的子进程。实际上是把mm、fs、files、signal这4个指针变量复制了一份到P2。
package main
impo RT (
"log"
"os"
"github.com/docker/docker/pkg/reexec"
)
var i =
func init() {
log. Printf ("init start, os.Args = %+v\n", os.Args)
reexec.Register("childProcess", childProcess)
if reexec.Init() {
os.Exit()
}
}
func childProcess() {
i =
log.Printf(": %v", i)
log.Println("childProcess")
}
func main() {
log.Printf("main start, os.Args = %+v\n", os.Args)
log.Printf(": %v", i)
cmd := reexec.Command("childProcess")
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Start(); err != nil {
log.Panicf("failed to run command: %s", err)
}
if err := cmd.Wait(); err != nil {
log.Panicf("failed to wait command: %s", err)
}
log.Printf(": %v", i)
log.Println("main exit")
}
输出结果为10、20、10。
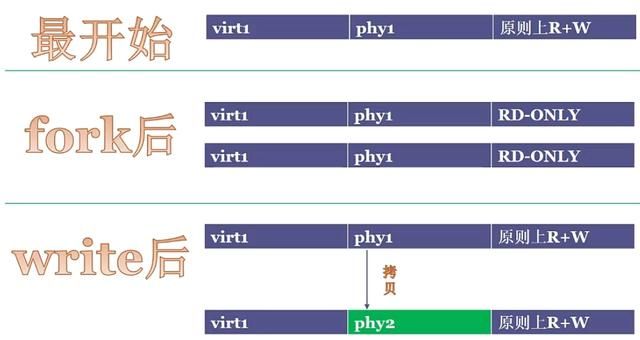
原因是:一开始变量i所在的数据段是可rw的,fork以后P1和P2数据段变成readonly,这时不管P1或P2谁去改变量i就会产生page fault缺页异常。这时就会copy变量i所在的page到新的物理地址,而P1和P2的虚拟地址保持不变。所以这个操作依赖有 MMU 内存管理单元的CPU。如下图所示:
- 吞吐vs响应
吞吐指的是尽量多做有用功,响应指的是及时任务切换。所以吞吐和响应是有矛盾的,如果你偏向响应那么必然之前任务停止做 有用功 。对吞吐和响应的偏向也产生了操作系统的服务器版和桌面版的区别。服务器版偏向吞吐,桌面版偏向响应,因为桌面用户体验必然是要求响应快。
进程可分为CPU bound和IO bound。IO bound的进程往往就偏向响应,因为往往是和用户体验相关。比如我动鼠标就死那边死活不动,那我气死了,电脑都给你丢掉楼下。所以IO bound的进程往往不需要CPU很强,只要能快速被调度响应即可。所以ARM架构的cpu就有个big.LITTLE架构。
偏向响应的话,context switch是很快的,但是容易造成cache miss,而内存相对于CPU寄存器来说很慢很慢,所以这样时间就长了,所以 server 会更偏向吞吐。
- 单核进程调度
linux内核有0-139优先级划分,其中0-99是RT进程(即real time),100-139是普通进程。
对于RT进程有两种调度方式:
sched_fifo:优先级高的跑到睡眠,优先级低的再跑。同等优先级先进先出,即先ready的先跑到睡眠然后下一个。
sched_rr:优先级高的跑到睡眠,优先级低的再跑。同等优先级轮转(round robin),即你一下我一下你一下我一下。
如果设置优先级是50,那么内核会用99-50是49,也就是优先级其实是49。
linux也不会让RT进程一直跑,那普通进程就没有机会了。所以有cat /proc/sys/kernel/sched_ rt _period_us默认1000000 微秒 ,cat /proc/sys/kernel/sched_rt_runtime_us默认950000微秒。意思是在period中最多能跑runtime时间。
对于100-139对应nice值-20-19。nice的意思是说善良,很nice,不争不抢还谦让。调度方式是rr,轮转。具体来说叫做CFS,即完全公平调度。
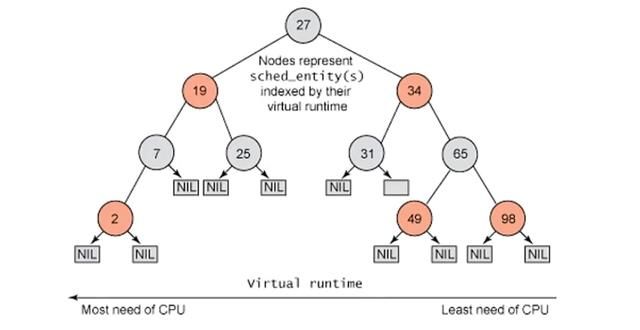
vruntime是虚拟运行时间。CFS把vruntime放到红黑树上。vruntime低的优先调度。
const int sched_prio_to_weight[] = {
/* - */ 88761, 71755, 56483, 46273, 36291,
/* - */ 29154, 23254, 18705, 14949, 11916,
/* - */ 9548, 7620, 6100, 4904, 3906,
/* - */ 3121, 2501, 1991, 1586, 1277,
/* */ 1024, 820, 655, 526, 423,
/* */ 335, 272, 215, 172, 137,
/* */ 110, 87, 70, 56, 45,
/* */ 36, 29, 23, 18, 15,
};
上表是nice值对应的weight,即权重值。
实际运行时间=调度周期*(权重/权重之和)
调度周期指的是全部ready的进程都跑一圈的时间。可见,nice值越小,权重越大,CPU占用也就越多,实际运行时间越长。
vruntime=(实际运行时间/权重)*1024
也就可以推导出:vruntime=(调度周期*(权重/权重之和)/权重)*1024=(调度周期*/权重之和)*1024
也就是说在一个调度周期内,虽然实际运行时间不同,但是vruntime是相同的。
进程的vruntime会进行累加,放到红黑树上。如果某个进程的vruntime小,说明某个调度周期它没参与,睡觉去了,所以linux就先调度它,追求vruntime的完全公平。
可以使用nice、renice设置进程的nice值来改变进程CPU占用。可以使用chrt命令把进程设置成RT级别从而提升调度。
- 多核进程调度
每个单核会按照rt_fifo、rt_rr、cfs的方法调度,多核上会进行负载均衡,可以push进程到别的核上执行,别的核也可以pull过来进程执行。当然,也可以设置核的affinity亲和性,比如 nginx 就能设置核亲和。可见,golang的运行时调度完全借鉴了linux的多核调度,可以work steal goroutine来执行。
再来看看cgroup。一个 cgroup 实际上就是一个task_struct群。比如,有一个进程A有10个线程,另一个进程B有2个线程。如果他们都是cpu bound型,根据cfs,12个线程平分CPU占用,那么其实是A进程占了10/(10+2),B进程占了2/(10+2),对于A和B来说不公平,所以可以把A放到一个cgroup里面,B放到另一个cgroup里面,这样A整体和B整体就公平调度了。
docker可以设置cgroup的period(期间)、quota(实际运行)、shares(就是weight)来设置CPU占用。
- linux不是硬实时系统
硬实时系统指的是有时间底线。比如按下按钮后必须在10ms内有反应。linux不是一个硬实时系统,因为linux有3个不可抢占task_struct的时候: 中断、软中断、spin lock ,也就是不可调度。所以linux不是硬实时系统。不过可以打硬实时补丁使得linux成为一个硬实时系统。