前言
我们上一篇文章中使用python-docx生成了一个word文档,里面涉及到了一些基础用法,我们这篇做一个查漏补缺,将里面的一些方法做一个简单的说明。
add_paragraph
这个方法是添加一个段落,我们找一首古诗,然后通过这个方式写入到word文档中
世人都晓神仙好,惟有功名忘不了! 古今将相在何方?荒冢一堆草没了。 世人都晓神仙好,只有金银忘不了! 终朝只恨聚无多,及到多时眼闭了。 世人都晓神仙好,只有姣妻忘不了! 君生日日说恩情,君死又随人去了。 世人都晓神仙好,只有儿孙忘不了! 痴心父母古来多,孝顺儿孙谁见了?
引自《红楼梦》
代码语言:python
复制
import docx
file = docx.Document()
file.add_paragraph("世人都晓神仙好,惟有功名忘不了!")
file.add_paragraph("古今将相在何方?荒冢一堆草没了。")
file.add_paragraph("世人都晓神仙好,只有金银忘不了!")
file.add_paragraph("终朝只恨聚无多,及到多时眼闭了。")
file.add_paragraph("世人都晓神仙好,只有姣妻忘不了!")
file.add_paragraph("君生日日说恩情,君死又随人去了。")
file.add_paragraph("世人都晓神仙好,只有儿孙忘不了!")
file.add_paragraph("痴心父母古来多,孝顺儿孙谁见了?")
file.save("好了歌.docx")
print("Word 生成完成")
代码非常简单,运行后的效果如下,每一行就是一个段落。
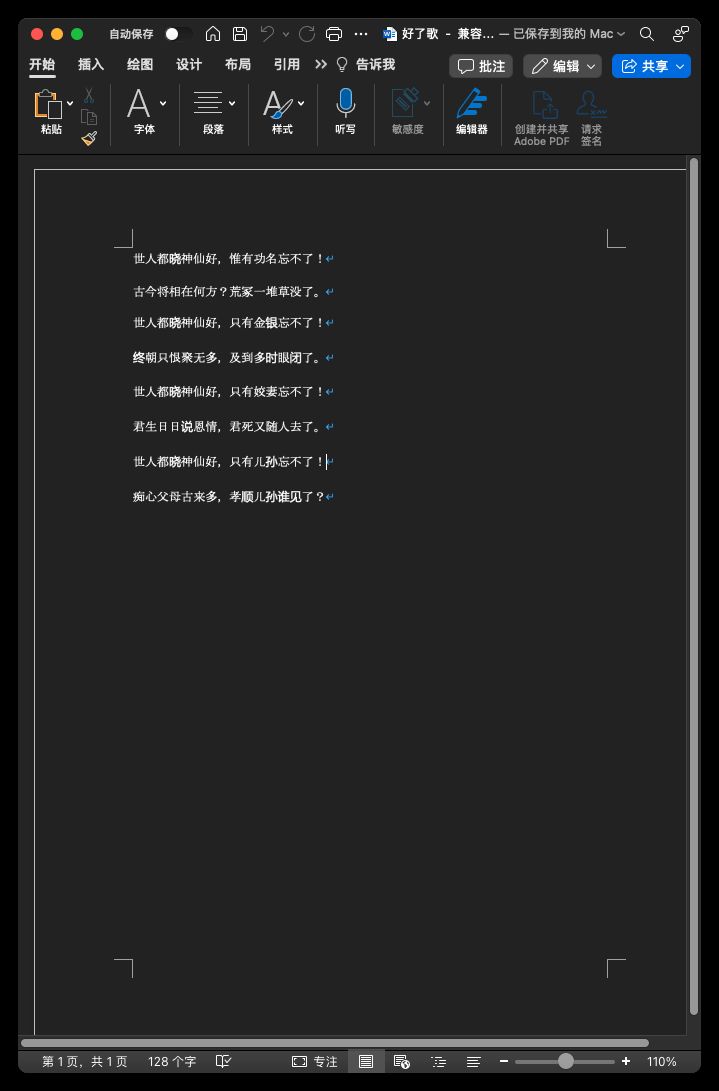
如果我们想打开一个文件,代码如下
代码语言:python
复制
import docx
file = docx.Document("好了歌.docx")
和创建文件不同的地方是在Document这个方法里面多了一个我们要打开的文件对象。
add_heading
这个方法是添加标题,我们尝试将好了歌/曹雪芹添加到刚刚生成的word文档中。
代码语言:python
复制
import docx
file = docx.Document("好了歌.docx")
file.add_heading("好了歌/曹雪芹", 0)
file.save("好了歌.docx")

我们看到这个方法虽然脚heading但它并不会自动的添加到文档的开头位置,这个需要注意一下。我指定了level为0,它默认是带下划线的。
add_picture
这个方法是向文中添加图片,这里就演示了,大家可以参考上一篇文章中的代码。
add_page_break
这个方法是添加分页符
代码语言:python
复制
file.add_page_break()
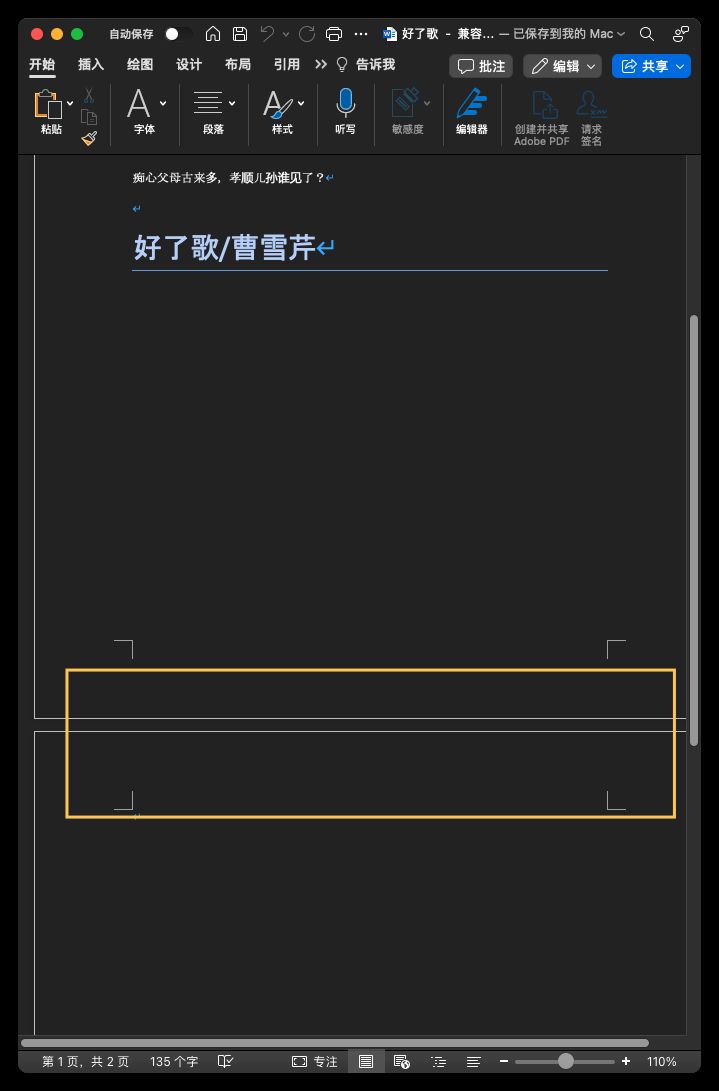
我们可以看到它新创建了一个空白页面。
add_table
这个方法是用来在word中创建表格的,主要有两个参数:rows代表行数,cols代表列数。我们来看一下,如果将上面那首诗用表格的形式展现该如何写
代码语言:python
复制
import docx
file = docx.Document()
table = file.add_table(rows=9, cols=2)
table.cell(0, 0).text = "世人都晓神仙好,"
table.cell(0, 1).text = "惟有功名忘不了!"
data = """\
古今将相在何方?荒冢一堆草没了。
世人都晓神仙好,只有金银忘不了!
终朝只恨聚无多,及到多时眼闭了。
世人都晓神仙好,只有姣妻忘不了!
君生日日说恩情,君死又随人去了。
世人都晓神仙好,只有儿孙忘不了!
痴心父母古来多,孝顺儿孙谁见了?
"""
for i, line in enumerate(data.split('\n')):
lin_str = line.strip()
if not lin_str:
continue
table.cell(i+1, 0).text = lin_str[:8]
table.cell(i+1, 1).text = lin_str[8:]
file.save('demo4.docx')
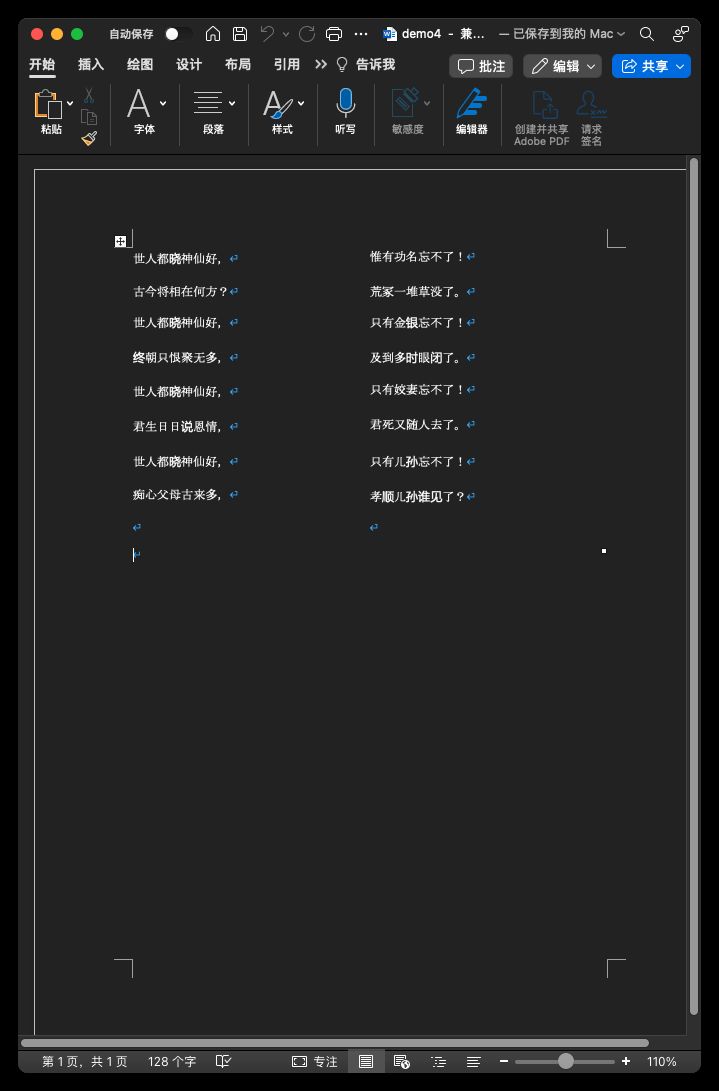
cell接收的两个参数分别代表行和列
这里为了省事就直接用循环来讲数据填充进去了,运行后效果如下
我们也可以通过下面这样的方式来读取文档内容
代码语言:python
复制
file = docx.Document('demo4.docx')
table = file.tables[0]
for row in table.rows:
for cell in row.cells:
print(cell.text)
如果不是表格的情况下也可以用下面这种方式
代码语言:python
复制
for p in file.paragraphs:
print(p.text)
最后
今天的内容就是这些了,我们简单的补充说明了一下这个库的基本用法,后面我们再把字体设置相关的内容说明一下,如果你对办公自动化感兴趣欢迎持续关注我,我们一起提高办公效率永不加班。
我是Tango,一个热爱分享技术的程序猿我们下期见。
我正在参与2024腾讯技术创作特训营第五期有奖征文,快来和我瓜分大奖!